EEGLAB データ構造
EEGLAB は、EEGLAB と EEGLAB を組み合わせてユーザーを対象としています。 MATLABの関数:(/tutorials/ConceptsGuide/EEGLAB_functions.html) EEG構造は、 高度なユーザーは、データを効率的に処理するためにそれらを使用することができます。
目次
- トピックス
はじめに
EEGLAB MATLAB は、EEGLAB MATLAB の略称です。 EEGLABデータ構造(EEG)とサブ構造(EEGLAB) EEG.data、EEG.event、EEG.urevent、EEG.epoch、EEG.chanlocs EEG.history は必須項目です。EEGLABのデータ構造は必須です。
- EEG: 現在のEEGデータセット
- AllEEG: 全てを 記憶する
- 現在のデータセット
- LASTCOM: EEGLABメニューが発行されました
- EEGLABメニューから発行されたすべてのコマンド
- STUDY:EEGLABグループの構造解析
- CURRENTSTUDY: EEGLABは、EEGLABが分析する1、一般公開テストを行なっています。
EEGLAB は、グローバル変数の定義です。 コマンドラインからアクセス可能ですが、グローバルでは利用できません。 EEGLAB の変数です。 主要な 相互 相互 EEGLABの機能 eeglab.mの (その他) display)関数 は、 入力パラメータは、グローバル変数にアクセスしたり変更したりしません。 望ましくない副作用を最小限に抑えます。 エフェクト
EEGとアレグ
EEGLAB 変数 EEG は、 MATLABの構造です。 現在の場所を選択 ファイル サブメニュー項目を押します 既存のデータセットをロードするEEGLABの「sample_data」フォルダにある「eeglab_data_epochs_ica.set」のチュートリアルファイルです。 EEG* コマンドを生成します。 ライン出力:
>> EEG
EEG =
setname: 'EEG Data epochs'
filename: 'eeglab_data_epochs_ica.set'
filepath: '/data/matlab/eeglab/sample_data/'
subject: ''
group: ''
condition: ''
session: []
comments: [9x769 character]
nbchan: 32
trials: 80
pnts: 384
srate: 128
xmin: -1
xmax: 1.9922
times: [1×384 double]
data: [32×384×80 single]
icaact: [32×384×80 single]
icawinv: [32×32 double]
icasphere: [32×32 double]
icaweights: [32×32 double]
icachansind: [1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32]
chanlocs: [1x32 struct]
urchanlocs: [1×32 struct]
chaninfo: [1×1 struct]
ref: 'common'
event: [1×157 struct]
urevent: [1×154 struct]
eventdescription: {[2×29 char] [2×63 char] [2×36 char] '' ''}
epoch: [1×80 struct]
epochdescription: {}
reject: [1×1 struct]
stats: [1×1 struct]
specdata: []
specicaact: []
splinefile: []
icasplinefile: ''
dipfit: []
history: ''
saved: 'yes'
etc: [1×1 struct]
datfile: 'eeglab_data_epochs_ica.fdt'
run: []
ヘルプメッセージを見るには eeg_checkset.m 関数(一貫性をチェックする)を参照してください。 EEGLABデータセット
EEGLAB 変数 ALLEEG は、すべてのデータセットを MATLAB は、 現在の EEGLAB/MATLAB の作業現場です。 EEGデータセットの配列(上述) 。 MATLABのALLEEG* コマンドラインリターン:
ALLEEG =
1x2 struct array with fields:
setname
filename
filepath
pnts
nbchan
trials
srate
xmin
xmax
data
icawinv
icasphere
icaweights
icaact
event
epoch
chanlocs
comments
averef
rt
eventdescription
epochdescription
specdata
specicaact
reject
stats
splinefile
ref
history
urevent
times
タイピング >> AllEEG(1) は、データセットを読み込みます。 AllEEG と入力 >> allEEG(2) は 2 です。 データセット。 詳細はこちら EEGLABの歴史 もっとチュートリアルのセクション これらの構造を操作するための情報。 EEG構造のフィールド、値が点在しています。 eeg_checkset.m 関数)。しかし、EEGの項目 構造はサブ構造を含んでいます。 簡潔に3つを記述します ※EEG.chanlocs、EEG.event、EEG.epoch*
EEG.chanlocs(エグ)
EEG 構造フィールドは、EEG を構成します。 場所とチャンネル名。 例えば、チュートリアルデータセットをロードする と入力 >> EEG.chanlocs
>> EEG.chanlocs
ans =
1x32 struct array with fields:
theta
radius
labels
sph_theta
sph_phi
sph_radius
X
Y
Z
EEG.chanlocs は、32 の 設定を 行ないます。 このデータセットの32チャンネルのそれぞれ。
>>>EEG.chanloc(1) を参照して下さい。 リターン:
>> EEG.chanlocs(1)
ans =
theta: 0
radius: 0.4600
labels: 'FPz'
sph_theta: 0
sph_phi: 7.200
sph_radius: 1
X: 0.9921
Y: 0
Z: 0.1253
これらの値は、チャネルの位置座標とラベルを保存します。 チャンネル (‘FPz’). の の チャネル 機能またはメニュー項目 編集 → チャネルの場所 チャンネルの場所情報を編集または再入力する。 任意の値 MATLABが変更されました コマンドライン インポートのチュートリアルセクションも参照してください チャネルの場所.
EEGイベント
EEG 構造フィールド、実験、イベントの開催場所 データが記録されている間に発生し、追加可能 ユーザー定義イベント。 チュートリアルデータセットと入力を読み込みます。
>> EEG.event
ans =
1x157 struct array with fields:
type
position
latency
urevent
epoch
type、latency、および urevent は、 イベント構造:
- ※type* はイベントタイプです。
- latency は、データ内のイベントの位置(サンプルポイント)です。
- ureventは、’ur’はドイツ語の「元の」を意味し、EEG.urevent構造内の対応する元のイベントへのインデックスです。
position は、ユーザーが定義した実験内の位置です。
削除されたデータ部分について、フィールド duration ブレイク(境界線)イベントの期間を自動的に保存します。
データセットからエポックを抽出すると、イベントが属するデータエポックのインデックスを保存するために、別のフィールドepochが追加されます。
EEGLABのイベント構造について詳しくは、イベント処理のスクリプトチュートリアルを参照してください。
また、元のイベントを保持する別の構造体EEG.ureventもあります。urはドイツ語で「元の」を意味します。この構造体には、データセットに最初に読み込まれたイベント情報と、ユーザーが手動で追加したイベントが保存されます。連続データを最初に読み込んだ時点では、この構造体の内容はEEG.event構造体と同じです。ただし、EEG.event側にあるureventポインターフィールドは除きます。アーティファクト除去によってイベントがデータセットから削除されたり、データからエポックが抽出されたりすると、元の一部のイベントはEEG.urevent構造体の中にだけ残ります。
上のEEG.event構造体にあるureventフィールドは、同じイベントがEEG.urevent構造体配列のどこにあるかを示すインデックスです。たとえば、アーティファクト除去の際に2番目のureventを含むデータ部分が削除された場合、その2番目のイベントはEEG.event構造体には残りませんが、EEG.urevent構造体には残ります。このとき、データに残った2番目のイベントは元の3番目のイベントである可能性があるため、3番目のEEG.ureventにリンクされます。つまり、次のように確認できます。
>> EEG.event(2).urevent
ans =
3
イベントの種類
現在のデータ構造のイベントフィールドは、タイピングで表示できます。 >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> MATLAB で EEG.event 最初のイベントのフィールド値を表示するには、次のようにします。
>> EEG.event(1)
ans =
type: 'square'
position: 2
latency: 129.087
urevent: 1
イベント構造にカスタムイベントフィールドを追加できることを忘れないでください また、イベント情報を随時インポートします。 データセットをロードします。 そのため、一部のイベントフィールドの名前は異なる場合があります。 異なるデータセットで。 イベントフィールド情報を簡単にインポートすることができます。 例:
>> {EEG.event(1:5).type}
type フィールド の 5 で 返信します。
ans =
'square' 'square' 'rt' 'square' 'rt'
以下のコマンドを使用して、異なるイベントタイプをリストします。 加工されていないチュートリアルデータセット:
>> unique({EEG.event.type});
ans=
'rt' 'square'
上記のコマンドは、イベントタイプが文字列として記録されると仮定します。 使用条件 >> ユニーク(cell2mat({EEG.event.type})); 保存イベント 数字。
回復したイベント名を使用してエポックを抽出することができます。 詳細はこちら エポック抽出手順と同等のコマンドライン 上記のセクションで提示 データの抽出 epochs.
>> EEG = pop_epoch( EEG, { 'square' }, \[-1 2\], 'epochinfo', 'yes');
イベントのレイテンシー
上記のセクションで同じコマンドを使って表示することができます。 イベントレイテンシフィールドの内容。 イベントレイテンシーはユニットに保存されます データの標本は (1) 連続的な始まりに相対的にポイントします チュートリアルデータセット(オプション) 処理)、タイプ:
>> [EEG.event(1:5).latency]
ans =
129.0087 218.0087 267.5481 603.0087 659.9726
これらのレイテンシーを秒(上のサンプルポイントの代わりに)表示するには、 最初にこのセル配列を通常の数値配列に変換し、1 をサブトラクトする必要があります。 最初のサンプルポイントは0時間に対応し、サンプリングによる分割 レート。 そのため、
>> ([EEG.event(1:5).latency]-1)/EEG.srate
ans =
1.0001 1.6954 2.0824 4.7032 5.1482
一貫性のために、エポック化されたデータセットでは、イベントのレイテンシーも エポックタイムロックイベント(エポックの開始)からの相対的なサンプルポイントで保存されます。 データが連続していた場合と同様です。したがって、エポックを抽出した後 データ チュートリアル, 5 件のイベントレイテンシー:
>> {EEG.event(1:5).latency}
ans =
129 218.00 267.5394 424 513
,epochedデータセット 代わりに、メニュー項目を選択 編集 → イベントの値 (呼び出し機能) pop_editeventvals.m を公開しました。)表示する このイベントは、Epoch 時間ロックの秒単位です。 イベント コマンドラインから、関数を使うことができます。 eeg_point2lat.mの 指定したレイテンシーをデータから変換する 秒単位でデータの先頭に相対的なポイント エポックタイムロックイベントの相対的。 例えば:
>> eeg_point2lat(cell2mat({EEG.event(1:5).latency}), cell2mat({EEG.event(1:5).epoch}), EEG.srate, [EEG.xmin EEG.xmax])
ans =
0 0.6953 1.0823 -0.6953 0
逆変換は機能を使って達成することができます eeg_lat2point.mの.
便利な EEGLAB 関数 eeg_getepochevent.m は、任意のイベントフィールドを取得するために、連続およびエポックデータの両方に使用できます。 イベントの種類を問わずイベントフィールド 例えば、チュートリアルデータを使用する (エポック抽出後)、タイプ:
>> [rt_lat all_rt_lat] = eeg_getepochevent(EEG, 'rt', [], 'latency');
最初の出力は、各データエポックに指定されたタイプの最初のイベントのフィールド値を配列で返します。 2番目の出力はセル配列で、すべての関連イベントのフィールド値が各エポックに含まれています。 レイテンシー情報はミリ秒単位で返されます。 (注:第3入力で各エポックの特定の時間ウィンドウ内でイベントを検索できます。 空の場合は全エポックを検索します)。 ‘square’イベント’position’ は、 各エポックのイベント, タイプ:
>> [rt_lat, all_rt_lat] = eeg_getepochevent(EEG, 'square', [], 'position');
連続したデータは単一のデータエポックとして振る舞います。
>> [~, all_sq_lat] = eeg_getepochevent(EEG, 'square');
ドメインが無効な状態です。 (第二出力経由)
ウルビッツ
別の ‘ur’ (‘元の’ Deutsch) イベント EEG.ureventは、元々データセットに読み込まれたイベントの不変の記録です。 一部のイベントやデータ領域がデータから削除されても、EEG.ureventは影響を受けません。 新規イベントをデータセットに追加すると、ウレベント構造は自動的に更新されます。 これは実験のコンテキストを追跡するのに便利です。 データエポックを抽出した後でも、前の連続データのイベントコンテキストはEEG.urevent構造に保持されています。 コマンドラインから確認できます
EEG.ureventの構造はEEG.eventの構成要素です 構造。 イベント構造の* urevent* フィールド(例、 EEG.event(n).urevent は、 urevent 構造を組み立てる - イベントからイベントへの対応付け、 例えば元の連続データイベントストリーム内の「オリジナルイベント」の番号など。 例えば、データの一部が 連続データセットから2番目のイベントが削除されます。 アーティファクト拒否後、EEG.eventの第2イベントは削除されますが、 EEG.urevent構造には残ります。 例: EEG.eventの2番目のエントリはEEG.ureventの3番目を指します
>> EEG.event(2).urevent
ans =
3
EEG.event 構造の urevent の指定は利用できます 線形に増加して下さい。 例えば、エポックが抽出された後、 チュートリアルデータセット,
>> {EEG.event(1:5).urevent}
ans =
[1] [2] [3] [1] [2]
つまり、イベント1と2(最初のデータエポック)とイベント4 と5(第2のデータエポック内)は同じ元の イベント
EEGLAB は、 eeg_time2prev.m 関数, eeg_urlatency.m は そして、 eeg_context.m を参照してください。 EEG.urevent構造の詳細については、上記のチュートリアルセクションを参照してください。
イベントの境界
EEGLAB は、現在制作するイベントです。 データの部分が連続データから除外される場合や、 連続的なデータセットは連結されます。 これらのイベントは、 レイテンシーと(可能な場合)これらを中止する期間 データに導入した操作。 下の画像では、データの一部 ‘boundary’ は、 ‘boundary’ と ‘boundary’ を区別します。 イベント構造に追加。 イベントが行われるため、そのインデックスが2になりました。 レイテンシーでソート。 出口の構造は保持し続けます オリジナルイベントの開催
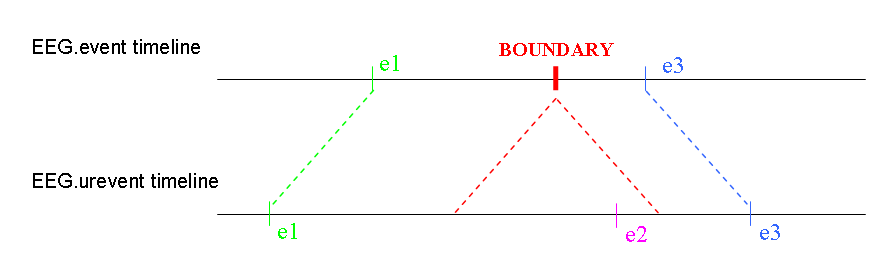
この図では、サンプル100から1950が削除され、境界イベントが100.5に挿入されました。
サンプル1〜1000のイベントは、レイテンシー0.5と1000.5に境界イベントを持ちます。
event.duration フィールド 拒否されたデータ部分(データサンプル)の期間。 それ以来 データセット内のすべてのイベントは、データセットで同じフィールドを持つ必要があります。 ‘ ‘ ‘ ‘ ‘ 真の境界型イベントを除き、デフォルトで0または空に設定します。 バウンダリー イベントは処理する複数の信号処理機能によって使用されます 連続データ。 例えば、データのスペクトルを計算する pop_spectopo.m は、 機能は連続した部分だけで作動します データ(境界イベント間で)。 また、データエッチング機能 境界イベントを含むエポックを抽出しません。
Epoched データでは、各エポックのイベントは チャンネル×サンプル×エポックの3D形式で保存され、 データを連続していれば、2次元配列としてデータを処理する効果 フォーマットの処理は コマンドラインからのイベントは便利です。
EEG.ures は、 以下に示すように、元の連続データから実験的なイベント。 ファンクション eeg_context.m 関数 urevents 構造体 近隣イベントのコンテキストで定義されたイベントを見つけるための情報 実験(元のデータ)
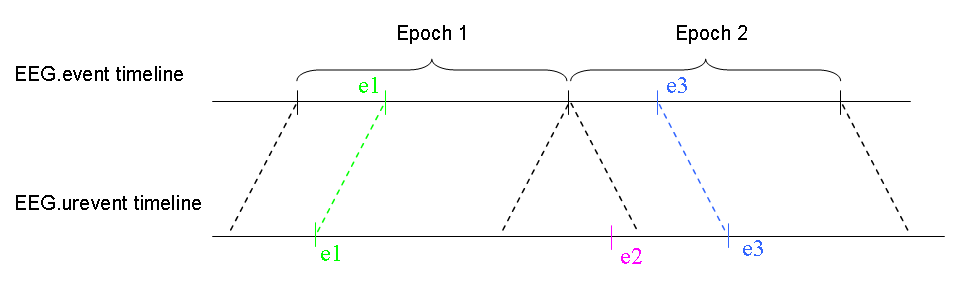
データセット間の「ハード」境界。 連続したデータセットが連結されると、境界の「ハードル」タイプ EEG.event および、 EEG.urevent は必須項目です。 特に 最初の 最初の ペアは1つのデータセットで最後のイベントでした。次のイベントは 次の連結データセットで最初のイベント(不要) 同時に録音)、隣接するペアのレイテンシー 尿素は直接比較できません。 いわゆる「ハード」境界 連結データセット間でのジョイントをマークするイベントは、通常どおり type ‘boundary’ が、 ‘duration’ 値、 NaN (MATLAB 数値) ‘not-a-number’ は、 ‘not-a-number’) を持ちます。 EEG.ureventの「ハード」境界イベントは、EEG.eventの「boundary」タイプで、 ‘NaN’ と EEG.event.urevent ポインタの ‘duration’ の 使い方 尿道。 ハードドライブの「境界」イベントは、などの機能のために重要です eeg_context.m 関数 一時的な関係に関係する 実験中のイベント(例:ウレベント)
EEG.epochの特長
EEG.epoch 構造は、Everデータセットで、 エポックエキス 機能 * EEG.event* 構造から計算される eeg_checkset.m 関数 (付き) ‘eventconsistency’ を、使用して、 EEGLAB のドキュメントを参照してください。 EEG.epochの構造の詳細は eeg_context.m にあります。 エントリーは必須項目です。 epoch は、エポック化されたデータセットでのみ存在します。 変換後に設定したチュートリアルで次の例を実行しました データエポックに。
>> EEG.epoch
ans =
1x80 struct array with fields:
event
eventlatency
eventposition
eventtype
eventurevent
このデータセットには80個のエポック(またはトライアル)が含まれています。 タイプ:
>> EEG.epoch(1)
ans =
event: [1 2 3]
eventlatency: {[0] [695.3125] [1.0823e+03]}
eventposition: {[2] [2] [2]}
eventtype: {'square' 'square' 'rt'}
eventurevent: {[1] [2] [3]}
ユニバースフィールド EEG.epoch(1).event 最新ニュース エポックは、このフィールド EEG.epoch(1).eventtype, EEG.epoch(1).eventposition およびEEG.epoch(1).eventlatency は療法です イベントの各イベントのイベントフィールド値を含む配列 エポック。 EEG.epoch(1).eventlatencyのレイテンシーは エポックタイムロックイベントに関するミリ秒。
EEG.epoch.eventduration は、 ミリ秒単位のイベント。 このフォーマットは異なることに注意してください ※フレーム保存EEG.event.duration*(表示) 秒またはミリ秒。
エポックを抽出するときは、すべて削除することができますが、選択したセット データからのイベント。 例えば、イベントが1つしかない場合 epoch は、epoch が読み込まれています。 データエポック抽出後のデータセット、項目選択 編集 → 選択する epoch/event メニューで、入力します(ポップアップで) ‘rt’ を Event type で選択します。 イベントの削除、イベントの削除* イベント * * Ok、新しいデータセット。 注意: この娘(そしてその将来の子供のデータセット、もしあれば)は痕跡を含まない (EEG.urevent) 実験中は、この工程で消去された。
その後、タイピング
>> EEG.epoch(1)
フィードバック
ans =
event: 1
eventlatency: 1.0823e+03
eventposition: 2
eventtype: 'rt'
eventurevent: 3
‘rt’ の 1 個の 1 個の ‘rt’ の 1 個の ‘t’ の ‘ の 1 個の ‘t’ の ‘ が 1 個 である。 1082.3 ms. また、, これは イベント データセット(例:event:1)は、イベントのテーマを組み合わせる 元データセットが対応しています。 EEG.event.ureventは3です。
保存された .set ファイル
EEGLABデータセットは、.setファイルです。 .setは、MATLABファイルです。
save -mat myfile.set EEG
EEGLABのデフォルト設定では、20
save -mat myfile.set -struct EEG
.fdt ファイルは .float32 形式でデータを保存します。 .fdt の別の形式については、EEGLABのドキュメントを参照してください。
data = EEG.data;
EEG.data = 'myfile.fdt';
floatwrite(data(:,:)', 'myfile.fdt');
save -mat myfile.set EEG
機能によって実行される追加のチェックがあります pop_loadset.m 関数EEGLABのデータセットを読み込みます。
EEG = pop_loadset('myfile.set')
STUDYについて
EEGLABでは、カスタムMATLAB、関数、プラグインを操作する STUDY構造とディスタセット。
※STUDY* 構造体、各データセットの材料は、 すべてのデータセットの処理を可能にする追加情報 STUDY構造体は以下のとおりです。 小さなサンプルスタディセットの解析から得られた例 10つのデータセット、各5つの被験者から2つの条件を比較し、ダウンロードできます。 詳しくはこちら (1.8 GB)。 関数を使用してスタディセットをロードした後(前のセクションを参照するか、または下述のように) pop_loadstudyMATLABのSTUDY*を入力 コマンドラインは以下のような結果を生み出します。
>> STUDY
STUDY =
name: 'N400STUDY'
filename: 'N400.study'
filepath: '/eeglab/data/N400/'
datasetinfo: [1x10 struct]
session: []
subject: {1x5 cell}
group: {'old' 'young'}
condition: {'non-synonyms' 'synonyms'}
setind: [2x5 double]
cluster: [1x40 struct]
notes: ' '
task: 'Auditory task: Synonyms Vs. Non-synonyms, N400'
history: [1x4154 char]
etc: [1x1 struct]
STUDY.datasetinfo は、標準構造の配列です。 STUDYデータセット その被験者、条件、セッションを含むデータセットの1つについて、 グループラベル また、データセットファイル自体にポインタが含まれています (*詳細は以下に説明)
STUDY.datasetinfo 被験者、グループ、セッション* 条件 条件、対象グループ、セッション、ラベルを添付する 研究の各データセットに関連付けられている。 この情報は、 ※STUDY* 構造の作成はユーザが提供しました。 デフォルト値は想定されます。
STUDY.cluster はクラス構造の配列、初期化 STUDYが作成されます。クラスタリングは更新されます。 (*詳細は以下に説明) 独立したコンポーネントをクラスターした後、各データセット内の各識別されたコンポーネントが1つのコンポーネントクラスターに割り当てられます。 クラスタリングのために識別されるすべてのコンポーネントを含むクラスタ1。
STUDY.history は history と同等です。 EEG は、 . . . . 情報、参照 EEGLABの歴史 チュートリアルのセクション。
STUDY.etc フィールド、保存情報 STUDY構造はクラスタリング機能で 特に、クラスタリング前のプリクラスタデータが保存されます 実行する。
STUDY.datasetinfo サブ構造
STUDY.datasetinfo は、情報収集の目的です。 以下は、 構造、最初のデータセットに関する情報を保持する1 スタディ:
>> STUDY.datasetinfo(1)
ans =
filepath: '/eeglab/data/N400/S01/'
filename: 'syn01-S253-clean.set'
subject: 'S01'
group: 'young'
condition: 'synonyms'
session: 1
trialinfo: [1×426 struct]
comps: [3 5 6 7 8 9 11 13 14 15 16 17 19 20 21 24 25 28 29 34 35 44 52]
index: 1
STUDY は ユーザの投稿を受け付けています。
datasetinfo.filepath と datasetinfo.filename は ディスク上のデータセットの場所。
データセットinfo.subject フィールドは、 STUDY に複数のデータセットがある datasetinfo は、 異なる実験条件や/または表現として 異なる実験セッション。
datasetinfo.group は、対象グループを データセット。
datasetinfo.condition datasetinfo.session ホールフィールドド フィールドが空の場合、 すべてのデータセットは同じ条件を表すと仮定されます。 もし、 session フィールドは空で、ある程度の条件です。 異なるセッションで記録されていること。
datasetinfo.index は、ALLEEG です。 現在ロードされたデータセット構造のベクトル。 冗長ですが、 サブ構造が別の関数への入力として使用されるとき有用 (例: datasetinfo.index = 1 は ALLEEG(1)、*datasetinfo.index.= に対応)
datasetinfo.com は、コンポーネントのコンポーネントの構成要素です。 クラスタリングに指定されているデータセット。 空の場合、すべて そのコンポーネントはクラスター化される。
datasetinfo.trialinfo は、各個人を識別する トライアル 連続データが空です。 このフィールドでは、 与えられたデータセット内の試験との違いは、以下に記載されています。
>> STUDY.datasetinfo(1).trialinfo(1)
ans =
struct with fields:
chan: 0
description: 'syn'
duration: 128
points: 1
type: 'S253'
トライアル情報のデータ構造のフィールドはイベントのフィールドをミラーリングします フィールド ‘type’ は ‘duration’ です。 サンプルの刺激の提示の持続時間を示します。 その他 フィールド (‘chan’, ‘description’, ‘points’) は、 与えられたデータセット。 一般的に、異なるデータセットは異なる フィールド。
STUDY.design サブ構造
設計は、 可能(独立変数の選択を含む) 条件、グループ、セッション、特定の刺激関連試験、または サブセット。
STUDY.designサブ構造はこちら
>> STUDY.design(1)
ans =
name: 'Design 1 - compare letter types'
variable: [1x2 struct]
cases: [1x1 struct]
filepath: ''
include: {}
これらのサブ構造の各コンテンツの展開、取得
name: 'Design 1 - light and audio all subjects'
variable: [1x2 struct]
label: 'condition'
pairing: 'on'
value: {'ignore' 'memorize' 'probe'}
vartype: 'categorical'
cases: [1x1 struct]
label: 'subject'
value: {'S01' 'S02' 'S03' 'S04' 'S05' 'S06' }
include: {}
-
‘variable’ フィールドは、’独立変数の略です。’ 現在、 EEGLAB は、複数の変数を構成します。 特注品(LIMOEX) 統計を計算し、結果をプロットするために、任意の数 変数は、 STUDY.design(x).variable(1) STUDYについて 設計番号 x、STUDY.design(x).variable(2) は、 2番目の独立した変数の説明(もしあれば)。 詳しくはこちら 変数は “label” で、 と ‘off’ は、 タイプ(分類的または連続的) - 連続変数が EEGLAB は、EEGLAB でしか関連しません。 例えば、この特定の例では独立した変数 ‘条件’ は、’ignore’、’memorize’、’probe’ は、’probe’ は、’inore’、’memorize’、’probe’、’probe’、’probe’、’probe’、’inore’、’memorize’、’probe’、’probe’、’probe’、’、’probe’、’、’inore’、’、’、’memorize’、’、’probe’、’、’、’probe’、’、’、’、’probe’、’、’、’、’、’、’、’probe’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’、’ STUDY.design のドキュメントは、 値ラベルを連結し、それらを分離することによって結合される ‘-‘ 文字で。例えば、’memorize - Probe’ は新しい値です。 変数 ‘condition’ に、 変数 ‘condition’ に、 変数 ‘condition’ に 置く。 ‘memorize’ または ‘probe’ stimuli 。
-
‘cases’ は ‘cases’ を ‘cases’ に ‘cases’ と ‘cases’ を ‘cases’ で ‘cases’ と ‘cases’ 臨床研究の統計で採用される用語。 現在の使用 ‘cases’ は、 (単一の被験者をプロットするときは、使用するオプションを選択します) 統計のための単一の試験は「ケース」の同等を自動的に作ります ‘trials’ へ。
-
‘filepath’ は ‘filepath’ です。 保存される。
-
‘include’ フィールドは値と値です。 ‘memorize’ stimuli に ‘memorize’ stimuli 唯一の(およびすべての対象データセットを無視する)(または、シングルトライアルの場合) この独立した変数を持たない統計、すべての試験) 値。
STUDYの定義
STUDY* は、 STUDY. ‘condition’, ‘group’, ‘session’ は、 STUDY編集GUIで定義された変数。 変数、EEGLAB は、それぞれの変数を抽出します。 メールマガジン 各データセット。 関数 std_maketrialinfo.m の使い方 作成する *STUDY.datasetinfo の ‘trialinfo’ サブ構造 は、 STUDYは、
STUDY.datasetinfo(1).condition = 'a';
STUDY.datasetinfo(1).group = 'g1';
STUDY.datasetinfo(1).trialinfo(1).presentation = 'evoked';
STUDY.datasetinfo(1).trialinfo(2).presentation = 'evoked';
STUDY.datasetinfo(1).trialinfo(3).presentation = 'evoked';
STUDY.datasetinfo(1).trialinfo(4).presentation = 'spontaneous1';
STUDY.datasetinfo(1).trialinfo(5).presentation = 'spontaneous1';
STUDY.datasetinfo(1).trialinfo(6).presentation = 'spontaneous1';
STUDY.datasetinfo(1).trialinfo(7).presentation = 'spontaneous2';
STUDY.datasetinfo(1).trialinfo(8).presentation = 'spontaneous2';
STUDY.datasetinfo(1).trialinfo(9).presentation = 'spontaneous2';
‘trialinfo’ について 各試験施設について データセット番号 1. 試用番号1、2、3はプレゼンテーションタイプの試験です ‘evoked’, Whereas 試験 4, 5, 6 . . ‘spontaneous1’ と試用版 7、8、9 は、試用版版です。 ‘spontaneous2’。
関数 std_makedesign.m の使い方 またはそのGUI等 pop_studydesign.m を公開しました。)上記の情報を使用して作成します STUDY. ‘variable1’ のエントリの std_makedesign.m の使い方 ‘datasetinfo’ のフィールドか、 ‘datasetinfo.trialinfo’ のフィールド。’trialinfo’ のフィールドは、 STUDY.datasetinfo 構造のフィールドに似た方法 STUDY.datasetinfo は動作と定義です。
std_makedesign() を使用します。
>> STUDY = std_makedesign(STUDY, ALLEEG, 1, 'variable1', 'presentation');
「表示」の特定の値を選択するには、
>> STUDY = std_makedesign(STUDY, ALLEEG, 1, 'variable1', 'presentation', 'values1', { 'spontaneous1' 'spontaneous2' } );
STUDY.changrp サブ構造
STUDY.changrp サブ構造は、 STUDY.cluster は、 STUDY.changrp にデータ 重要な要素。各要素 STUDY.changrpは1つのデータです。 コンテンツ すべての被験者を横断するデータチャネル。 例えば、事前入力後 STUDY.changrp(1) をタイプするのは、
>> STUDY.changrp
ans =
1x14 struct array with fields:
name
channels
chaninds
changrp.name は、チャンネル名(‘FP1’) です。 changrp.channels は、この名前をつけます。 多岐に渡ります。 全体でRMSを計算します。
STUDY.cluサブ構造
STUDY.clusterのサブ構造は作成情報です。 STUDYのクラスタリング方法およびクラスタリング方法 STUDYデータセットのクラスタリング 複数のコンポーネントクラスターに割り当てられます。 異なったクラスターは空間的におよび/または機能的に明瞭であるかもしれません 記録されたデータの起源とダイナミクス。 例えば、1つのコンポーネント クラスターは、目の点滅のために考慮することができます, 目の動きのための別の, 第三 中央ポスターアルファバンド活動等のため 各クラスター 別の *STUDY.cluster フィールドに格納します。 STUDY.cluster(2)、STUDY.cluster(3)、等…
基本クラスター、STUDY.cluster(1) は、すべてのクラスターです。 クラスタリングのために識別されたすべてのデータセットから。 作成されました STUDYの作成、クラスタリングの手順 ParentCluster。 このクラスターは、そのコンポーネントは、 同等ダイポールモデルは、より高い割合の分散を発揮します コンポーネントのスカルプマップ。 これらのコンポーネントは除外されています クラスタリング(参照) コンポーネントのクラスタリング コンポーネントをクラスタリングから除外する方法の詳細については、チュートリアル。 STUDY.cluster* は、
>> STUDY.cluster
ans =
1x23 struct array with fields:
name [string]
parent [integer]
child [cell]
comps [array]
sets [array]
algorithm [cell]
preclust [struct]
topo [2-D array]
topox [array]
topoy [array]
topoall [cell]
topopol [array]
dipole [struct]
この情報(クラスタリング結果を含む)は、MATLABコマンドラインから、または対話的なpop_clustedit.m 関数を使ってアクセスできます。
EEGLAB 14では、各クラスターに関するより多くの情報(特定クラスターのERP、スペクトル、時間周波数データなど)が保存され、指定したクラスターをプロットしたときにこの構造体から利用できました。これらの配列はユーザーがアクセスできましたが、主にプロット用のキャッシュ値であり、プロットするたびに再読み込みしなくて済むようにするためのものでした。
EEGLAB 2019以降では、より単純なキャッシュ方式が採用され、プロット済みデータはすべてSTUDY.cache構造体に保存されます。データがSTUDYキャッシュ内にあれば、キャッシュされた値が自動的に返されます。この情報にアクセスするには、必要に応じてプロット表示を無効にしたうえで、std_erpplot、std_specplot、std_erspplotなどのプロット関数の戻り値を使うことが推奨されます。
各クラスターのcluster.nameサブフィールドは、 クラスター番号(例:クラスター配列のインデックス) ‘cls 2’,’cls 3’ など. (例: より有利な) pop_clustedit.m 関数 インターフェイス。
cluster.comps と cluster.sets は、 コンポーネントを 適切に管理します。 現在のクラスターは次のようになります: cluster.comps は、各データセットのコンポーネントインデックスを含みます。 複数のデータセットが同じ被験者で使用できることに注意してください。 コンポーネントの重みとスカルプマップ – 例えば2つのデータセットを含む 同じ被験者と異なる実験条件のデータ 同じ で で . . . cluster.sets* では 異なるデータセットインデックスを含む各行に複数の行が含まれる場合があります。
クラスター。preclust サブフィールドは、 クラスターに含まれるコンポーネントのプリクラスタ情報。 プリクラタリングメソッドは、 各パラメータ、結果処理PCAデータ matrices(例えば、コンポーネントERP、ERSP、および/またはITCを) 条件。 preclust構造追加情報 次のセクションで、その使用がさらに(階層) サブクラスタリングの説明
cluster.centroid は、クラスター測定の段階的な測定をします。 コンポーネントをクラスターするために使用される各測定(例、平均またはセンチロイド) 各クラスターコンポーネント ERSP、ERP、ITC、パワースペクトラなど STUDY条件)、クラスタリングの採用 相互クラスターの視覚化および編集機能のプロットのために利用できる、 pop_clustedit.m 関数.
cluster.algorithmサブフィールドは、クラスタリングをしています。 (例:kmeans) 事前にクラスタリングしたデータをクラスタリングします。
cluster.parent**cluster. および Child フィールドサブは 階層クラスタリング (参照) コンポーネントのクラスタリング チュートリアルのセクション)。
クラスター。子供 サブフィールドは、任意のクラスターのインスタンスです。 このクラスターからコンポーネントのクラスタリングによって作成される(おそらく、 cluster.parent フィールド 親クラスターのインデックスが含まれています。
cluster.topo**の フィールド が含まれています が含まれています は、6x6 で、6x6 は、 *cluster.topox cluster.topoy ([1x67])。 これは、スカルプに補間活性が含まれているので、異なる 電極位置をスキャンした被験者を視覚化できる クラスター。 topoall セルを1つにまとめる cluster.topopol は 各コンポーネントの極性脂肪-1sと1sの配列。 コンポーネントの極性は固定されません。 コンポーネントのアクティビティとそのスカルプマップは、バックプロジェクションを変更しません データチャネルへのコンポーネント) 真の頭皮の極性は取られます プロフィール
最後に、cluster. dipole 構造は、同等で コンポーネントクラスターのダイポール位置。 この構造は同じです 単一のコンポーネントのダイポール(参照) ソース チュートリアルのセクション)。
クラスター2(artifacts)は4つの構成要素から成る段階の構成要素です。 cluster は、 値:
>> STUDY.cluster(2)
ans =
name: 'artifacts'
parent: {'ParentCluster 1'}
child: {'muscle 4' 'eye 5' 'heart 6'}
comps: [6 10 15 23 1 5 20 4 8 11 17 25 3 4 12]
sets: [1 1 1 1 2 2 2 3 3 3 3 3 4 4 4]
algorithm: {'Kmeans' [2]}
preclust: [1x1 struct]
この構造フィールド情報は、このクラスターが他にはないと言います ParentCluster(注記、クラスター1)parentクラスター 3つ子クラスター(クラスター4、5、6)があります。 によって作られました ‘Kmeans’ algorithm および 公開されたクラスターが ‘2’ である。 EEGLAB 2019 出展のお知らせ 建物は、 クラスタリング。 多くの場合、単純なクラスタリングは、同様の結果またはより良い結果を得ることができます。
STUDY.cluster(2).preclustにプリクラタリングを保管してください。 サブ構造(上図ではなく下図)。 例えば、 ,cluster. preclust* サブ構造, PCA-reduced パーソクトラ(各2条件) クラスター内のすべての15コンポーネント。
cluster.preclust サブ構造、フィールド。 例:
>> STUDY.cluster(2).preclust
ans =
preclustdata: [15x10 double]
preclustparams: { {1x9 cell} }
preclustcomps: {1x4 cell}
preclustparams は、Cellの配列の配列です。 が含まれています が含まれています が含まれています が含まれています コンポーネント スペクトラ(spec)、コンポーネント ersps (ersp)、等)、 この例は1つのセル配列のみです。1つの測定のみです。 パワースペクトラム)はクラスタリングで使用されました。
例えば:
>> STUDY.cluster(1).preclust.preclustparams
ans =
'spec' 'npca' [10] 'norm' [1] 'weight' [1] 'freqrange' [3 25]
この例では、クラスタリングに使用されたデータ測定値は、指定した周波数範囲('freqrange' [3 25])のコンポーネントスペクトルです。スペクトルは10個の主成分次元('npca' [10])に縮約され、正規化('norm' [1])され、重み1('weight' [1])が割り当てられています。クラスタリングに複数の測定方法を使用する場合、preclustparamsには複数のセル配列が含まれます。
preclust.preclustdataフィールドには、クラスタリングアルゴリズム(Kmeans)に渡されたデータが入ります。この例のデータサイズは、ICAコンポーネント数(15) x スペクトルから保持した主成分数(10)です。冗長性を避けるため、ここにはクラスター内の15個のコンポーネントの測定値だけが残されます。他のコンポーネントの測定データは、それぞれのクラスターに保持されます。
preclust.preclustcompsフィールドは、サイズ(nsubjects x nsessions)のセル配列です。各セルには、クラスタリング対象となったコンポーネント、つまり親クラスターに含まれるすべてのコンポーネントが保存されます。
STUDYターターの.sets、.compsのサブ構造の
この * * * * * vSTUDY.cluster(クラスト).sets* と STUDY.cluster(クラスト).comps 与えられたクラスターに含まれるコンポーネントのリスト。 STUDY.cluster(クラスト).setsは[datasets_with_same_ica x ncomps]です。 対応するデータセットのインデックスを与える行列 STUDY.datasetinfo は必須項目です。 STUDY.cluster(クラスト) および comps。 STUDY.cluster(クラスト).sets ※STUDY.cluster(clust).comps* は必須です。 STUDY.cluster(clust).sets は、データセットのインデックスを与える行列です。 各コンポーネントが2つのデータセットに含まれている場合(同じ被験者の異なる条件など)、
>> STUDY.cluster(clust)
ans =
name: 'Cls 3'
sets: [2x13 double]
comps: [23 5 13 47 38 3 50 5 12 4 11 3 5]
parent: {'Parentcluster 1'}
STUDY.cluster(clust).sets*は、 いくつかの被験者は、同じ分解といくつかのデータセットを持っています 他の被験者は、同じデータセットの異なる数のコンポーネントを持っています。 これらの欠落したデータセットの存在は、いくつかの分析を破る可能性があります(警告メッセージが関連するときに表示されます)。
STUDYデータファイル
STUDY* は、 ディスクに保存 これらのファイルには、次のような名前があります。
S01.daterp % ERP data for data channels
S01.icaerp % ERP data for ICA components
S01.datspec % Spetrum data for data channels
S01.icaspec % Spetrum data for ICA components
S01.dattimef % Single-trial time-frequency data for data channels
S01.icatimef % Single-trial time-frequency data for ICA components
S01.daterpim % ERPIMAGE data for data channels
S01.icaerpim % ERPIMAGE data for ICA components
S01.icatopo % ICA component topographies
S01 は、STUDY の被験者名のプレフィックスです。 このファイルは ‘xx01’ 形式で命名されます。 単に数字(1, 2, 3, 等)であるべきではない理由もあります。 ほとんどのオペレーティングシステムは、起動するファイルを保存することができません 番号。
EEGLABのネーミング 2019年12月12日(水)、13日(金)、14日(日) 各STUDYは、対応する機器(有料) EEGLAB 2019以降では、EEGLAB がリリースされました。 2つの追加ファイルxxxx.daterspとxxxx.datitc* 平均的な時間頻度分解 - すべてのファイルが含まれているので 単一トリルデータ、これらのファイルは削除されました。
ファイル構造は、以下のすべてのファイルタイプに似ています。
>> fileContent = load('-mat', 'S01.daterp');
>> fileContent
ans =
chan1: [750×784 single]
chan2: [750×784 single]
chan3: [750×784 single]
chan4: [750×784 single]
chan5: [750×784 single]
...
chan70: [750×784 single]
chan71: [750×784 single]
labels: {1×71 cell}
times: [1×750 double]
datatype: 'ERP'
parameters: {'rmcomps' {1×3 cell} 'interp' [1×71 struct]}
datafiles: {'/data/data/STUDIES/STERN/S01/Memorize.set' '/data/data/STUDIES/STERN/S01/Ignore.set' '/data/data/STUDIES/STERN/S01/Probe.set'}
trialinfo: [1×784 struct]
chanxx は、アメリカ向けです。 コンポーネントの場合、プレフィックスは コンプリート の代わりに チャン を使用します。詳しくはこちら . . . . . 追加フィールドの説明:
- labels: ‘Cz’ ‘Pz’ などのラベルは、 このフィールドは、データチャネルのみに存在し、 ICAコンポーネントを提示します。
- データ型: このフィールドには、ファイルに保存されたデータの種類が含まれています。 ニュース 以下に詳細が記載されています。
- パラメータ:各測定値が計算されます。 MATLAB は、 実際のところ、 実際のところ、 実際のところ、 実際のところ、 実際のところ、 実際のところ、 実際のところ、 実際のところ、 実際のところ、 実際のところ、 実際のところ、 実際のところ、 実際のところ、 実際のところ、 実際のところ…
- datafile:このドキュメントは、
- trialinfo:個々のデータが似ているので、 STUDY.dataset(STUDY.dataset)(情報も含む) 条件、グループおよびセッションは別に貯えられます *STUDY.dataset は必須項目です。
フィールドデータ型は複数の値を取ることができます。
- ERP:ERPデータ
- SPECTRUM: SPECTRUMデータ(レガシー)
- 時間F:時間の頻度データ
- ERPIMAGE:ERPIMAGEデータ
ERPIMAGEデータでは、compおよびchanフィールドに文字列が含まれる場合があります。この場合、その文字列を実行してデータを読み込みます。これにより、必要がない場合に単一試行データを複数回保存することを避けられます。