前回の解析では、第1レベルの変数としてface_typeを選択しました(図7)。この方法では、ベータパラメータは各顔タイプの平均反応を表します。しかし反復効果があることもわかっており、ある反復が他より大きく異なる場合、平均が偏る可能性があります。既知の効果をすべて含む完全なデザインを作成し、条件をプールするコントラストを作成することを常に推奨します。
{kind=link}
第1レベル
この実験には9つの条件があります。有名な顔の1回目、2回目、3回目、スクランブル顔の1回目、2回目、3回目、未知の顔の1回目、2回目、3回目です。ここでは反復レベルをプールし、有名な顔、スクランブル顔、未知の顔という3条件だけを作成します。デザイン自体は6条件で実行されますが、反復レベルのベータパラメータを平均する3つのコントラストも作成されます。結果はよく似るはずですが、完全に同じではありません。
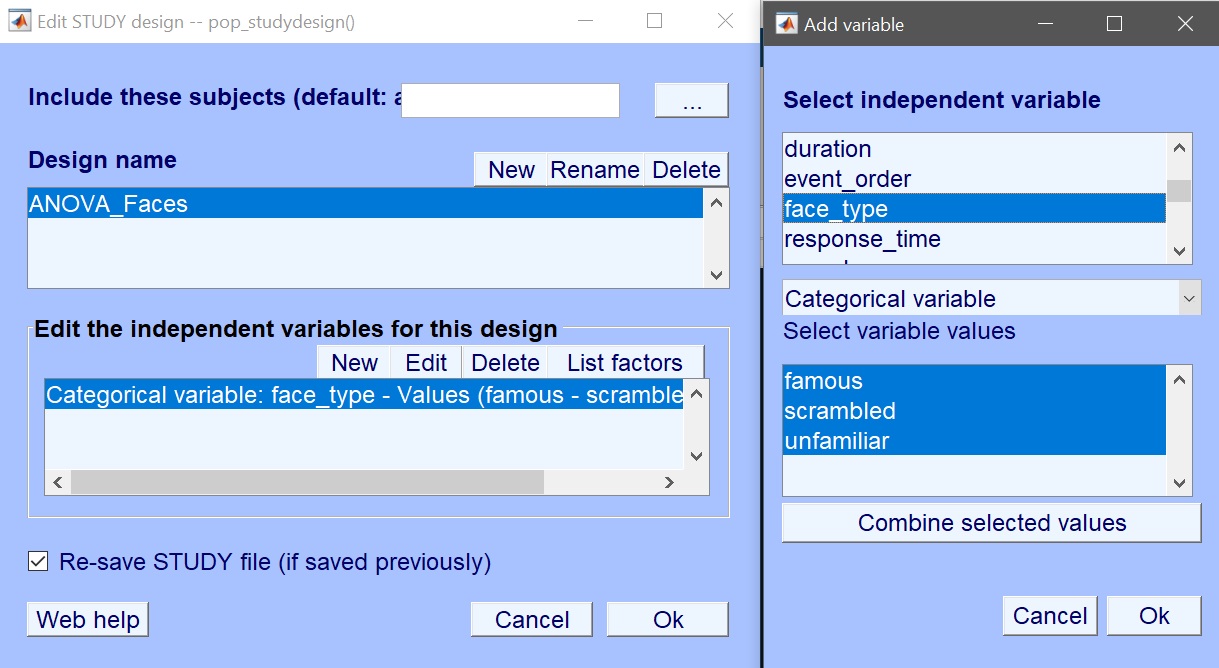
STUDYから新しいデザインを作成し、それを「FaceRepAll」と呼び、次に「new」をクリックして条件を追加します。 図 18.
 図 18. 新しいデザインのプール条件
図 18. 新しいデザインのプール条件
関心の変数は、9つの実験条件を含む「trial_type」です。 これらの条件を選択する代わりに、ここで繰り返しレベルを組み合わせてみましょう。 「有名・ニュー」、「有名・セカンド・イヤー」、および「有名・セカンド・レイト」を選択し、選択された値(コンバイン)をクリックします。図 19)。 スクランブルと未知の顔を繰り返します。 3つの新しい値を作成します。図 20) あなたの設計のために今選ぶ。
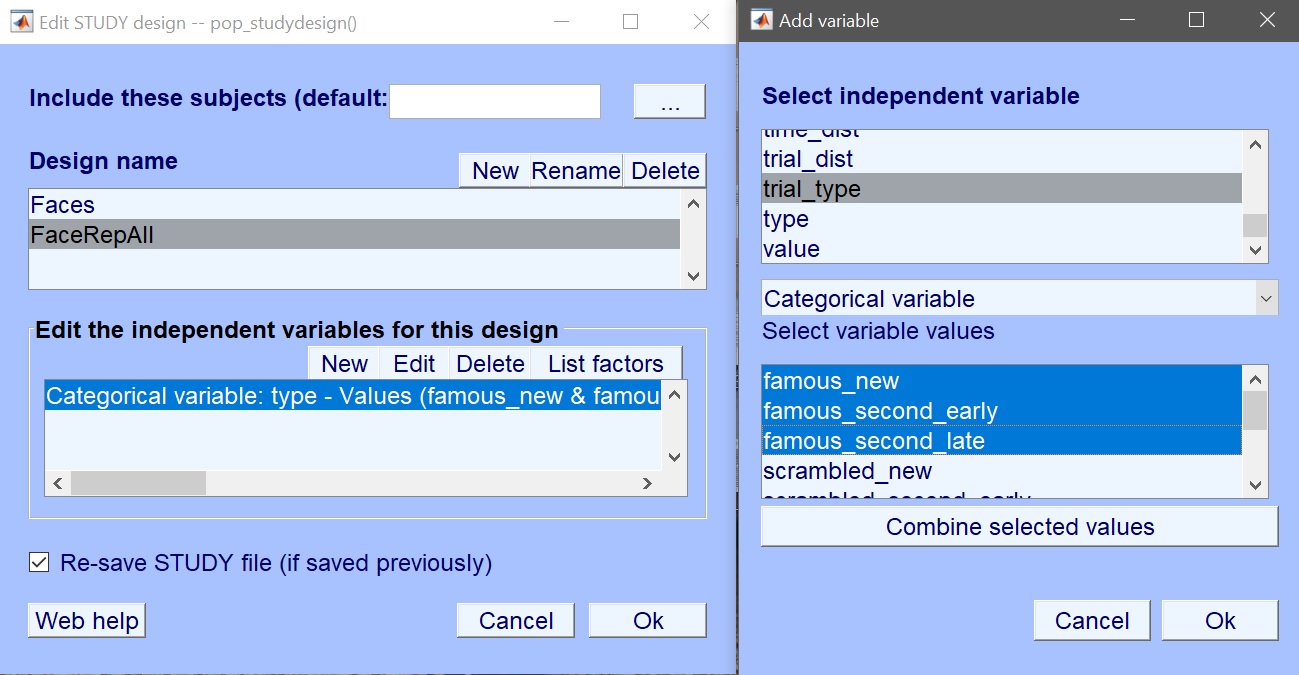 Figure 19. トライアルタイプで新しいデザイン
Figure 19. トライアルタイプで新しいデザイン
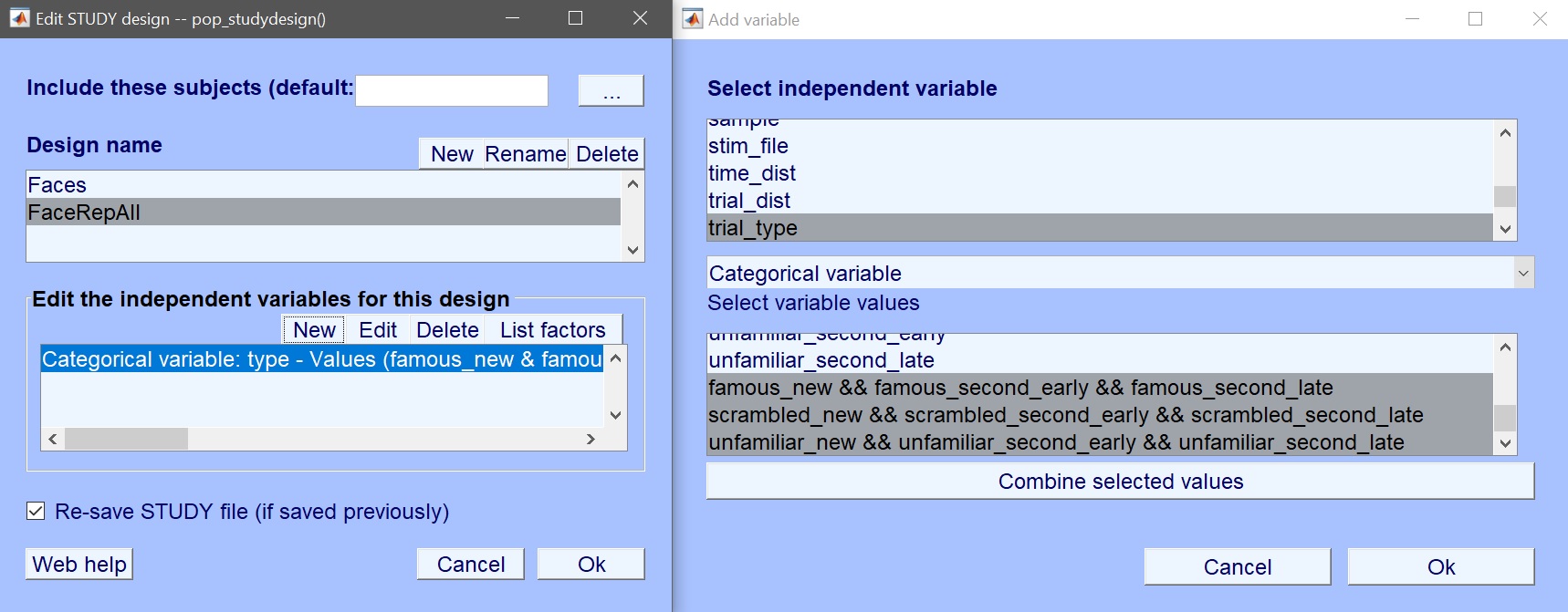 Figure 20. 試用型の組み合わせ値を使う
Figure 20. 試用型の組み合わせ値を使う
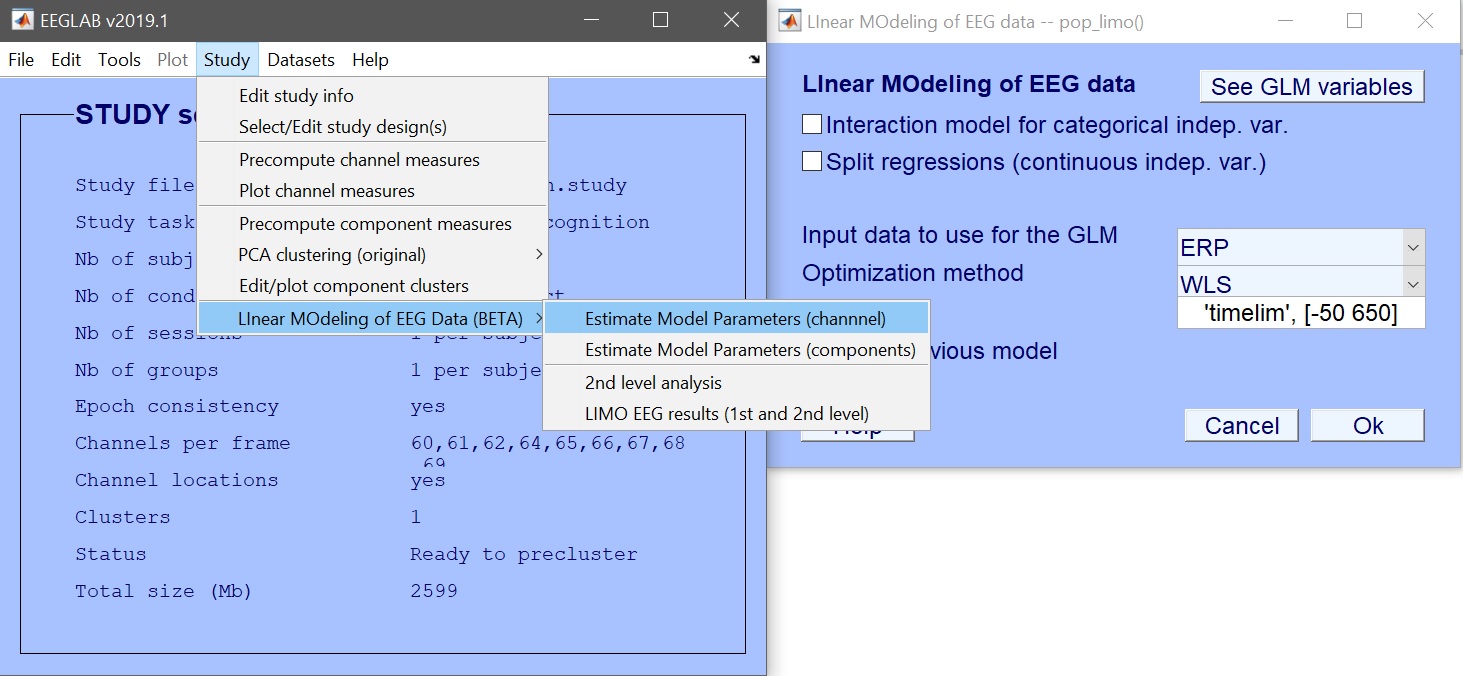
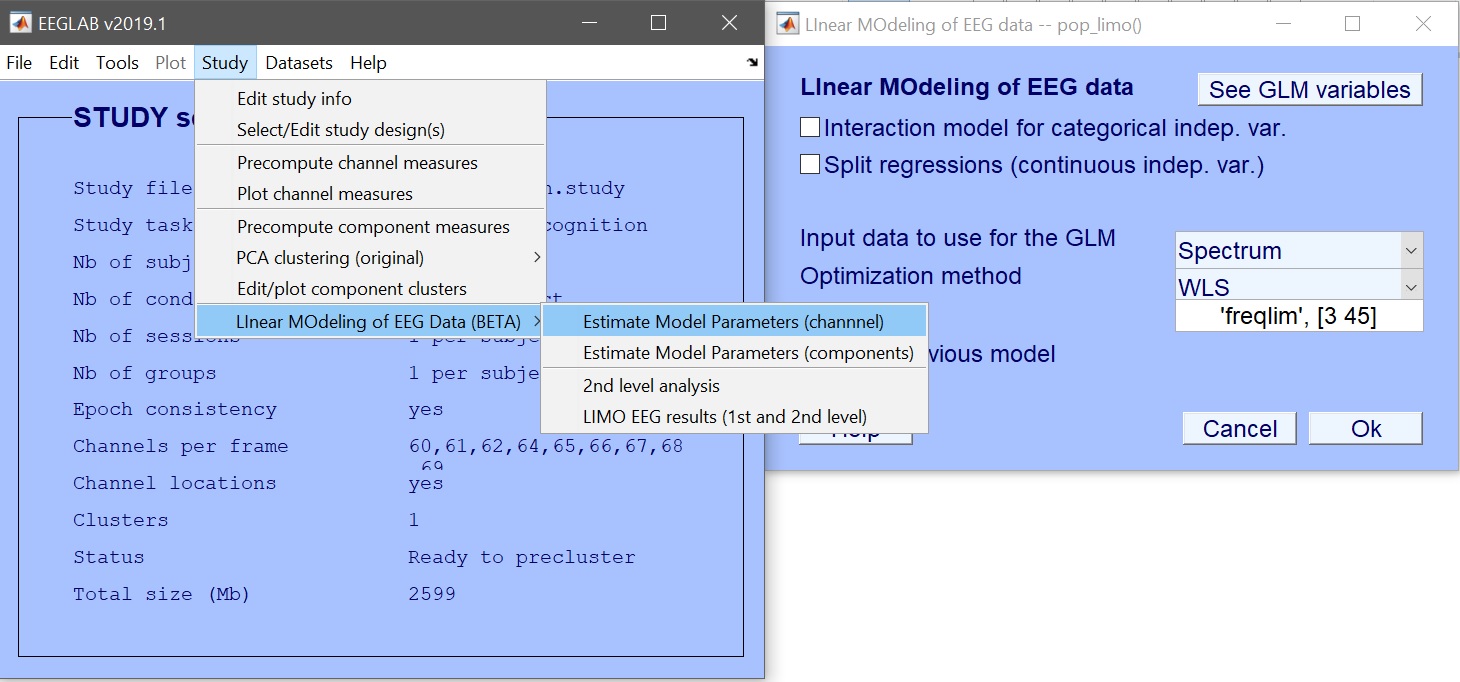
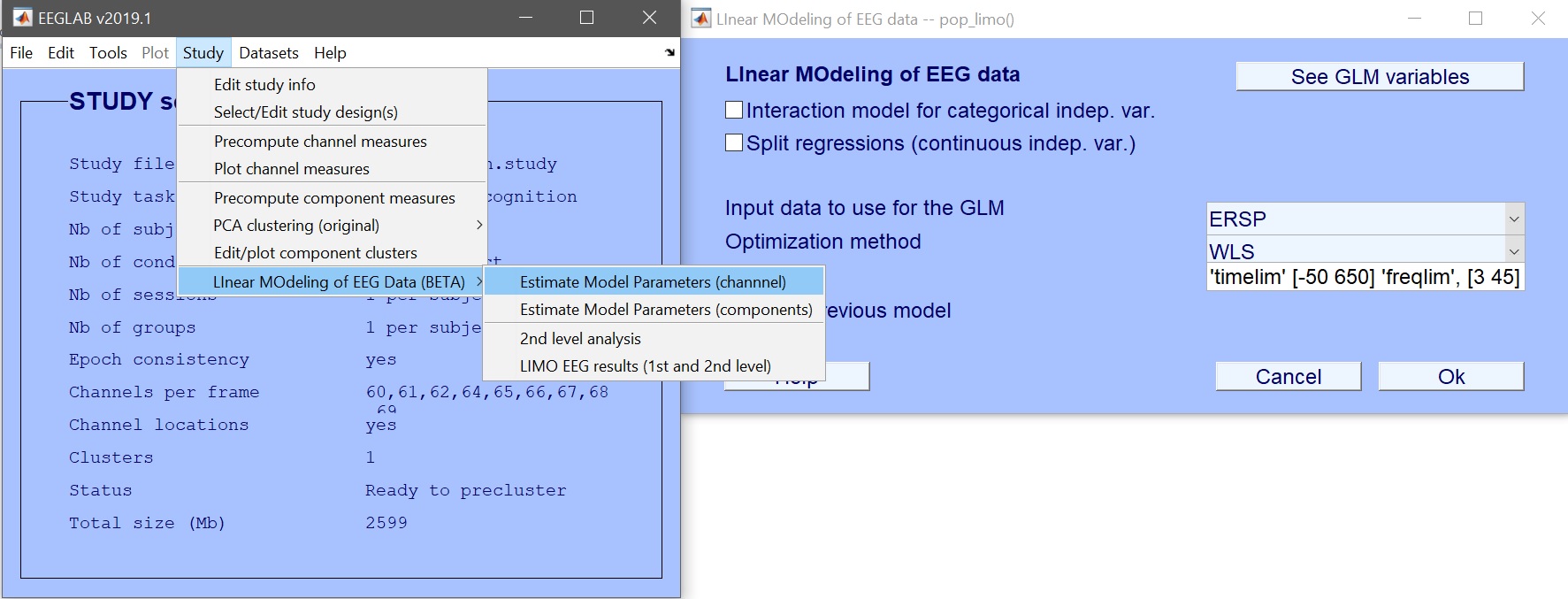
モデルパラメータを推定します。データ型としてERP、スペクトル、またはERSPを入力し、必要に応じて時間範囲または周波数範囲を制限します。デフォルトのWeighted Least Squares (WLS)は、データフレーム数より試行数が多い限り推奨される方法です。ベータパラメータに加えて、プールされた反復レベルに対応する3つのcon.matファイルが作成されます。
{kind=link}
{kind=link}
{kind=link}
% 1st level analysis - specify the design
% Note we use the variable 'type' and use cells within a cell array to
% indicate grouping which means contrasts will be computed pooling those levels
STUDY = std_makedesign(STUDY, ALLEEG, 2, 'name','FaceRepAll','delfiles','off','defaultdesign','off',...
'variable1','type','values1',{{'famous_new','famous_second_early','famous_second_late'},...
{'scrambled_new','scrambled_second_early','scrambled_second_late'},...
{'unfamiliar_new','unfamiliar_second_early','unfamiliar_second_late'}},'vartype1','categorical',...
'subjselect',{'sub-002','sub-003','sub-004','sub-005','sub-006','sub-007','sub-008','sub-009',...
'sub-010','sub-011','sub-012','sub-013','sub-014','sub-015','sub-016','sub-017','sub-018','sub-019'});
[STUDY, EEG] = pop_savestudy( STUDY, EEG, 'savemode','resave');
% 1st level analysis - estimate parameters
% ERP
[STUDY] = pop_limo(STUDY, ALLEEG, 'method','WLS','measure','daterp','timelim',[-50 650], ...
'erase','on','splitreg','off','interaction','off');
% Spectrum
[STUDY] = pop_limo(STUDY, ALLEEG, 'method','WLS','measure','daterp','freqlim',[3 45], ...
'erase','on','splitreg','off','interaction','off');
% ERSP
[STUDY] = pop_limo(STUDY, ALLEEG, 'method','WLS','measure','daterp','timelim',[-50 650],'freqlim',[3 45], ...
'erase','on','splitreg','off','interaction','off');
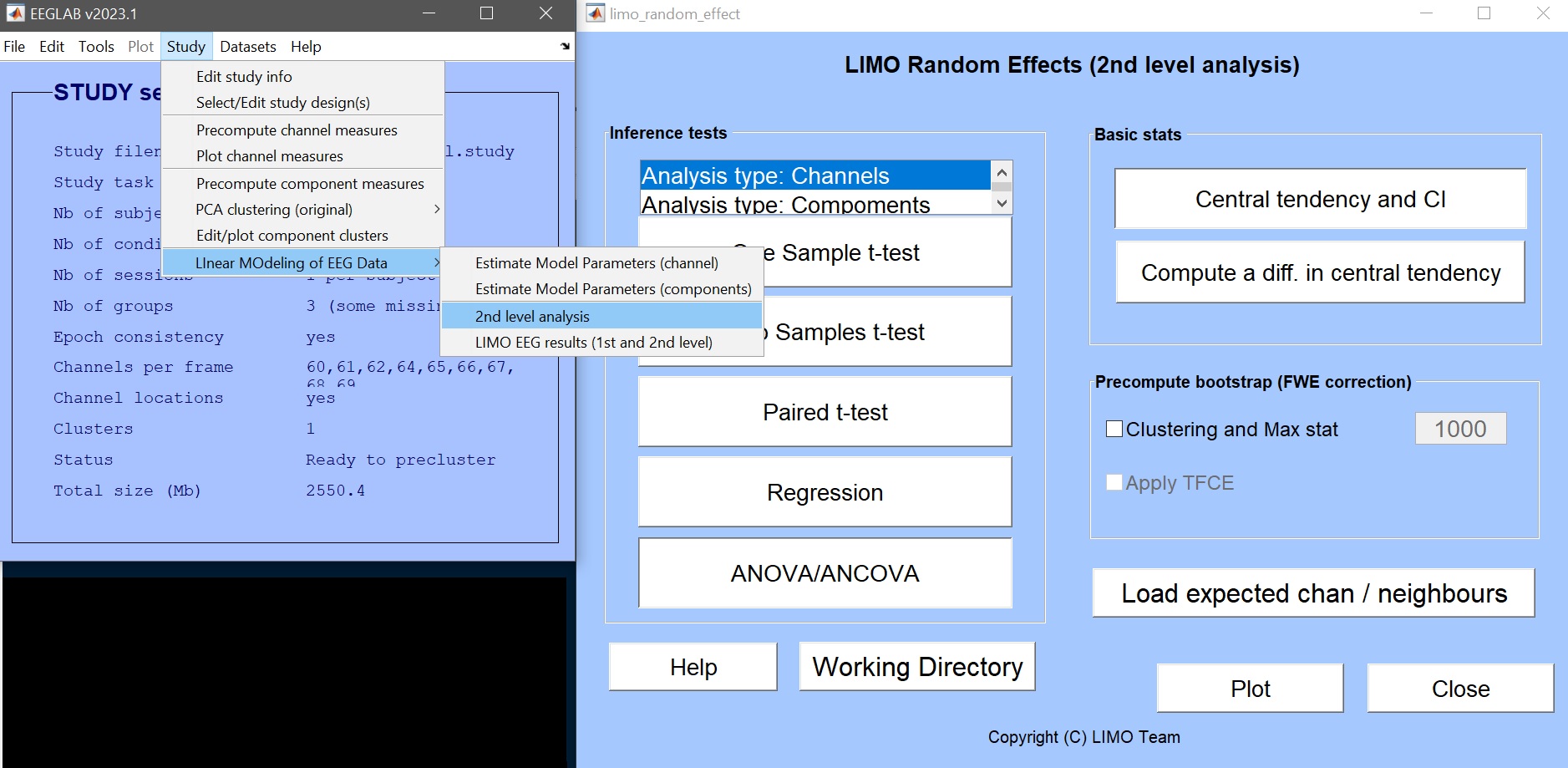
第2レベル
研究クリック –> EEGデータの線形移動 –> 2ndレベル分析()図9).
{kind=link}
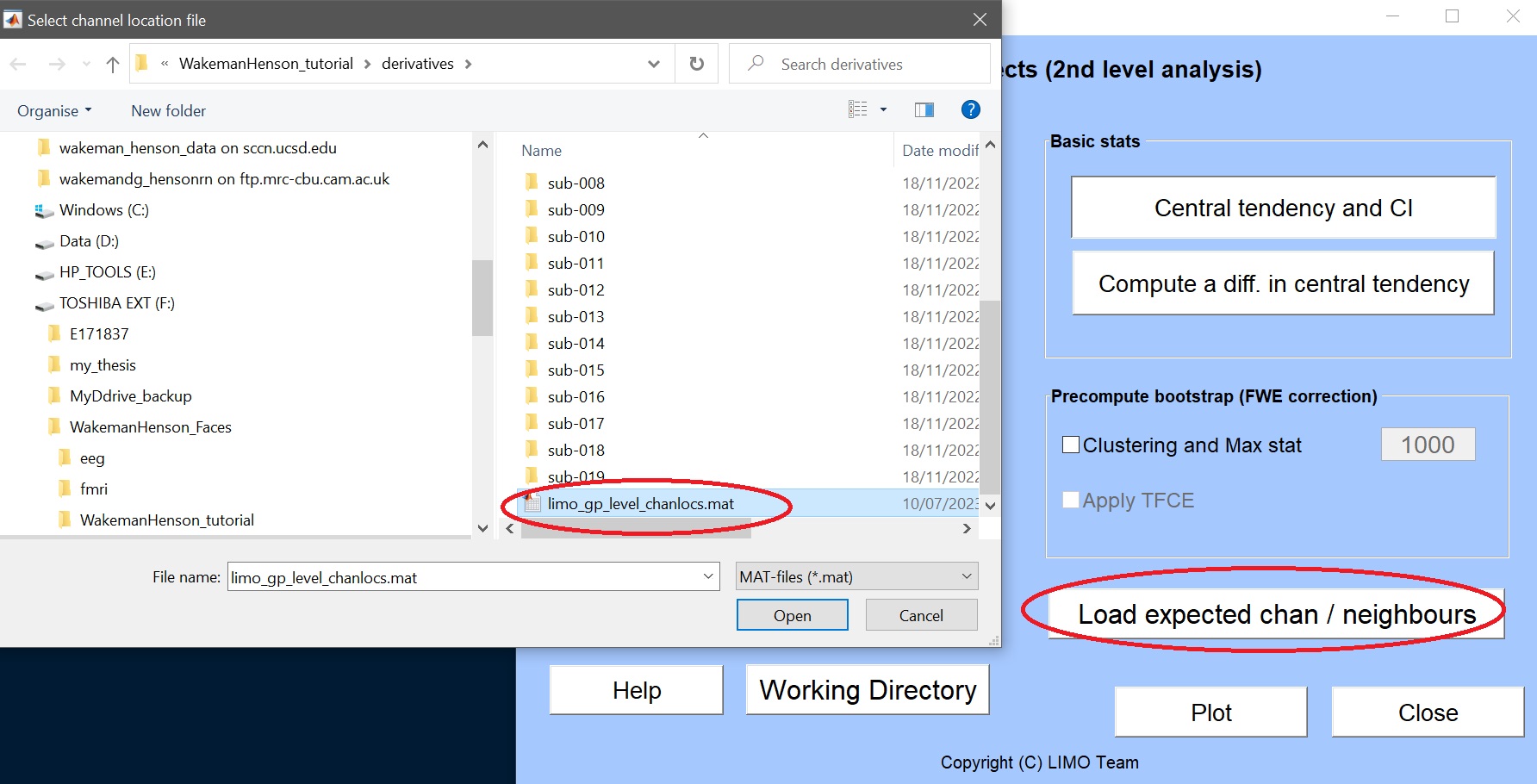
- グループレベルのチャンネルの場所ファイルをロードします。これは、デリバティブフォルダのルートにあるはずです()図10)
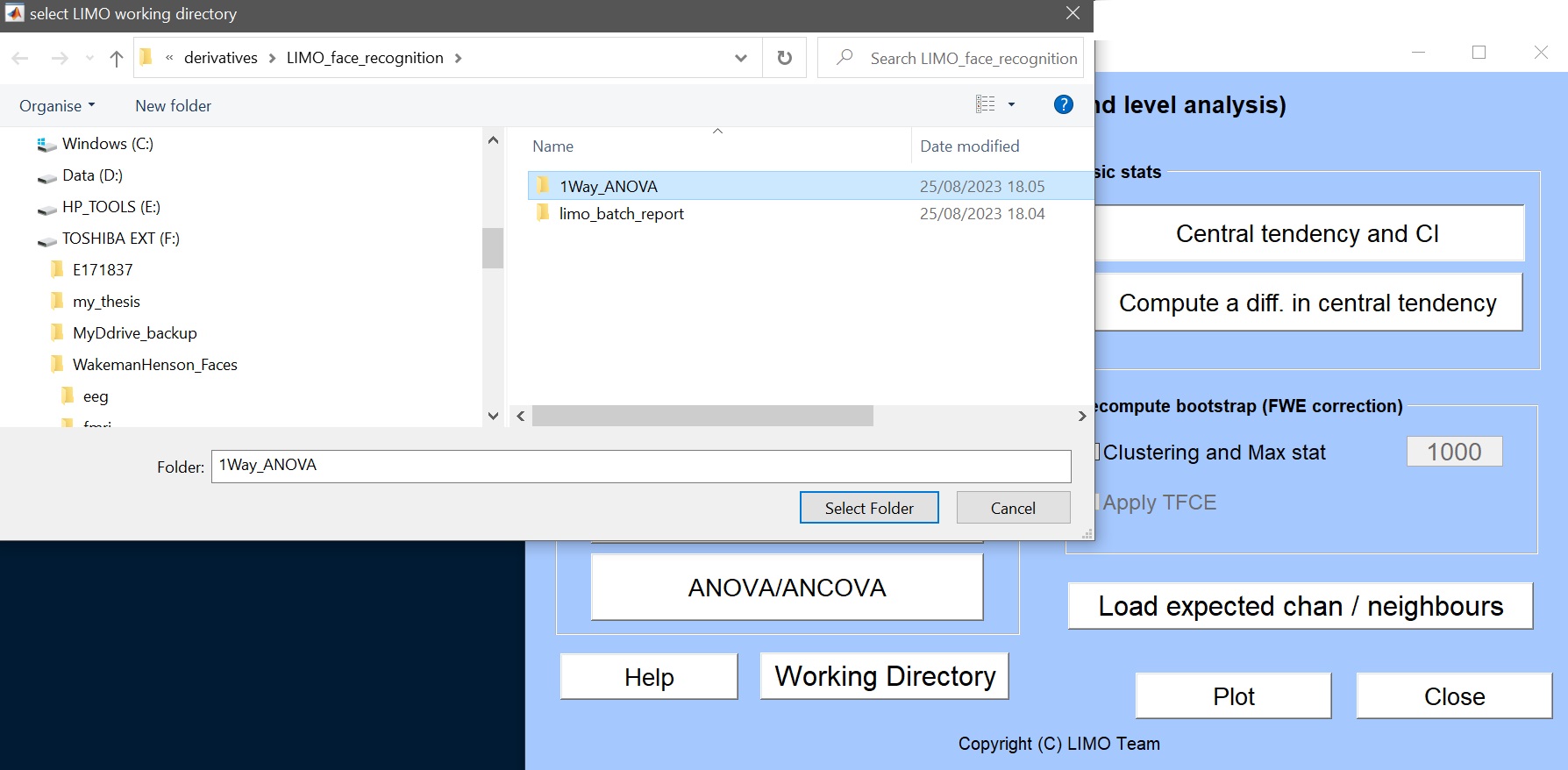
- この新しい解析を保存し、これを作業ディレクトリ(‘1way_ANOVA_revised’)として選択するために、新しいディレクトリ(‘1way_ANOVA_revised’)を作成します。図11)
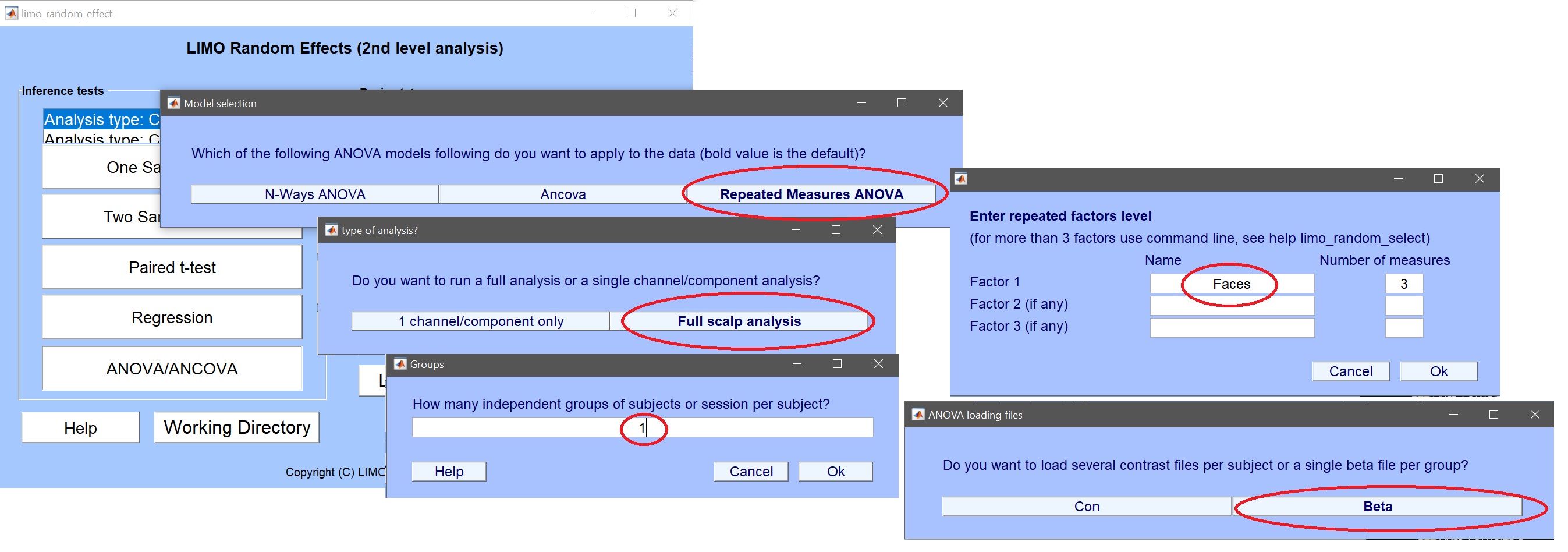
- ANOVA/ANCOVA をクリック図12) 必要に応じて情報を記入します。 フルスケール解析 –> 繰り返し測定 ANOVA –> 1 グループ –> 3 レベルの 1 つの要因
- 各レベルに反するファイルを選択します。図21)、「顔」という要素の名前
{kind=link}
{kind=link}
{kind=link}
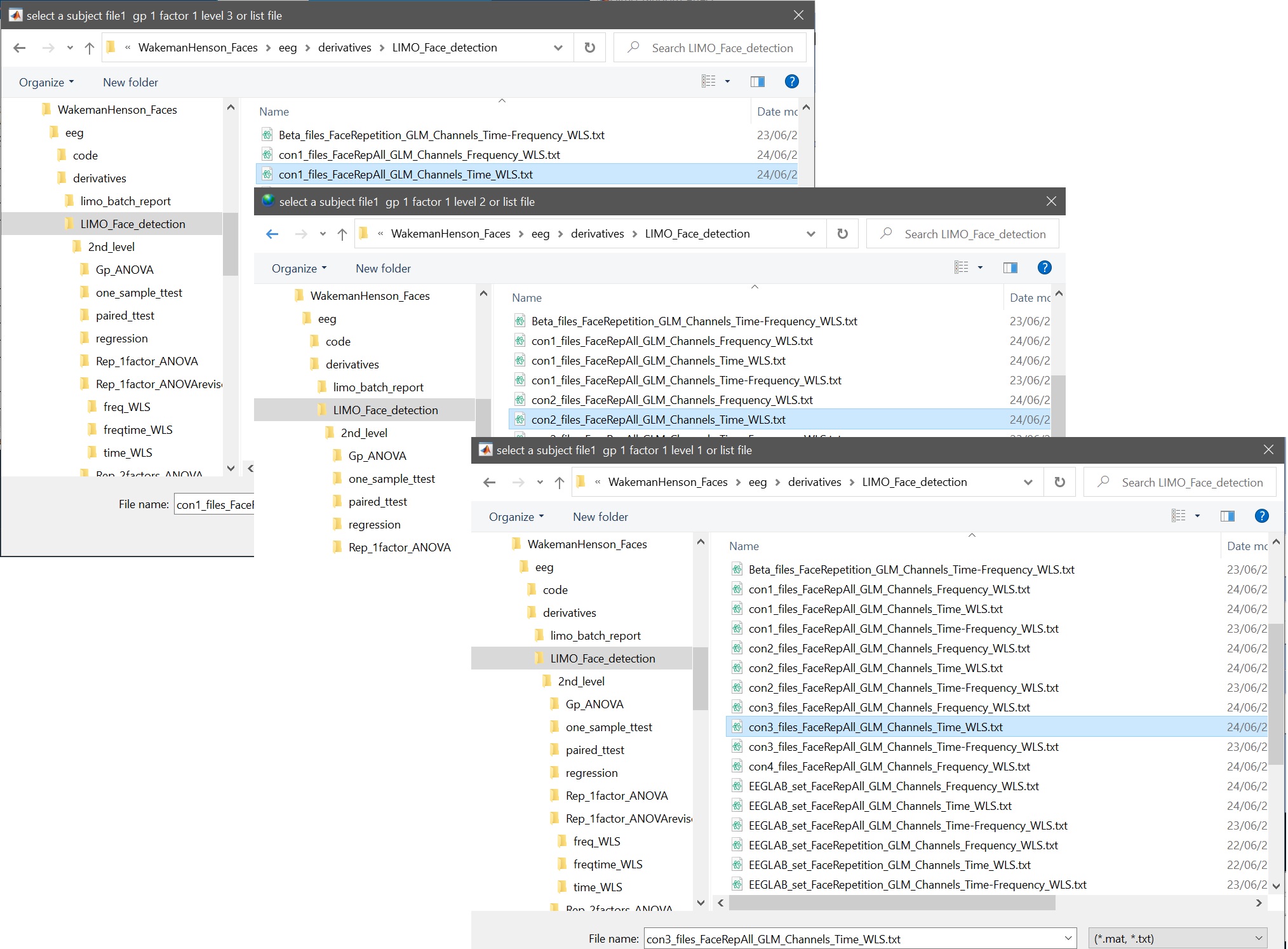 _Figure 21. ANOVA_のConファイル(ERP、すなわちチャンネルタイムWLS)を選択
_Figure 21. ANOVA_のConファイル(ERP、すなわちチャンネルタイムWLS)を選択
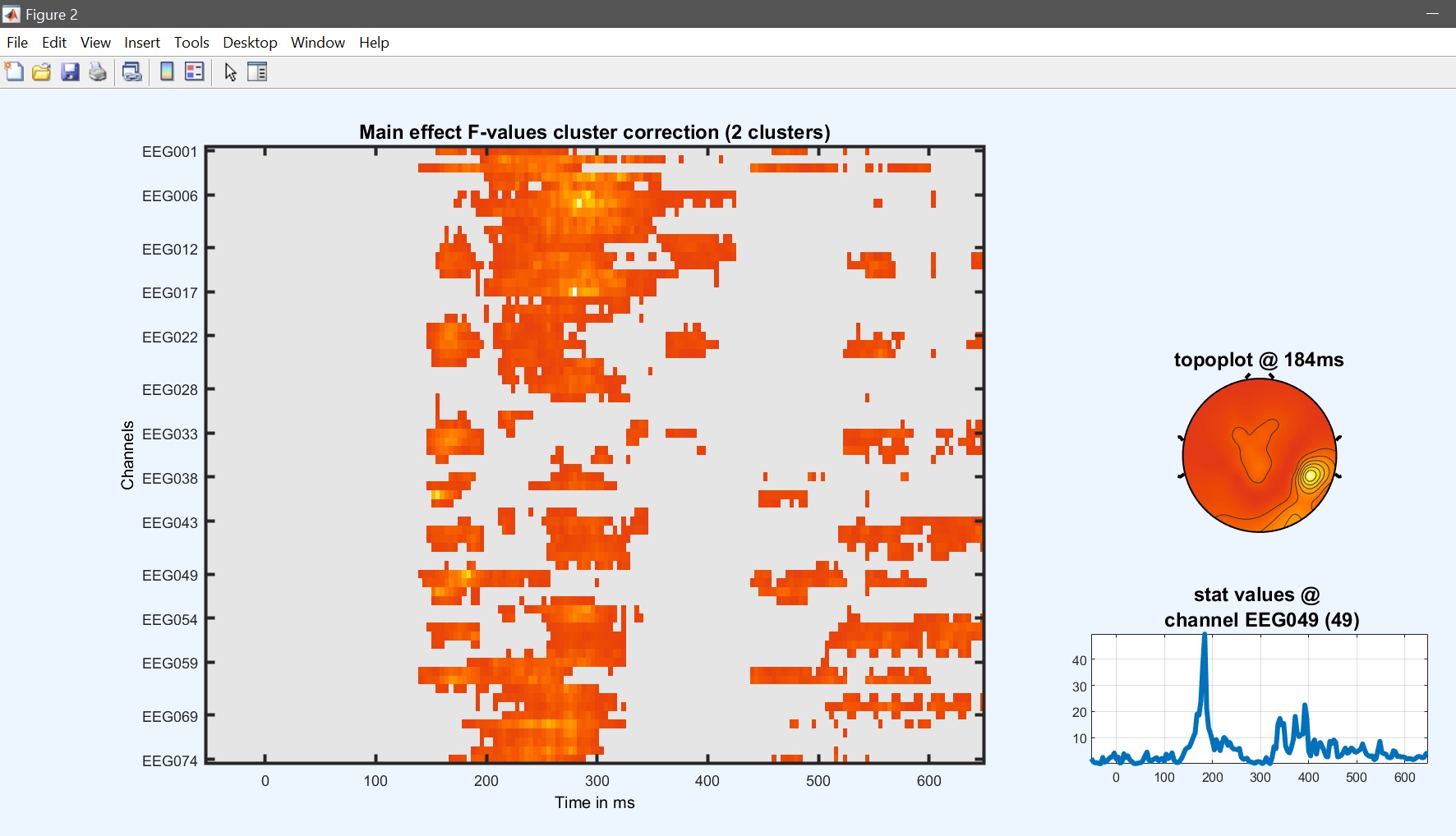
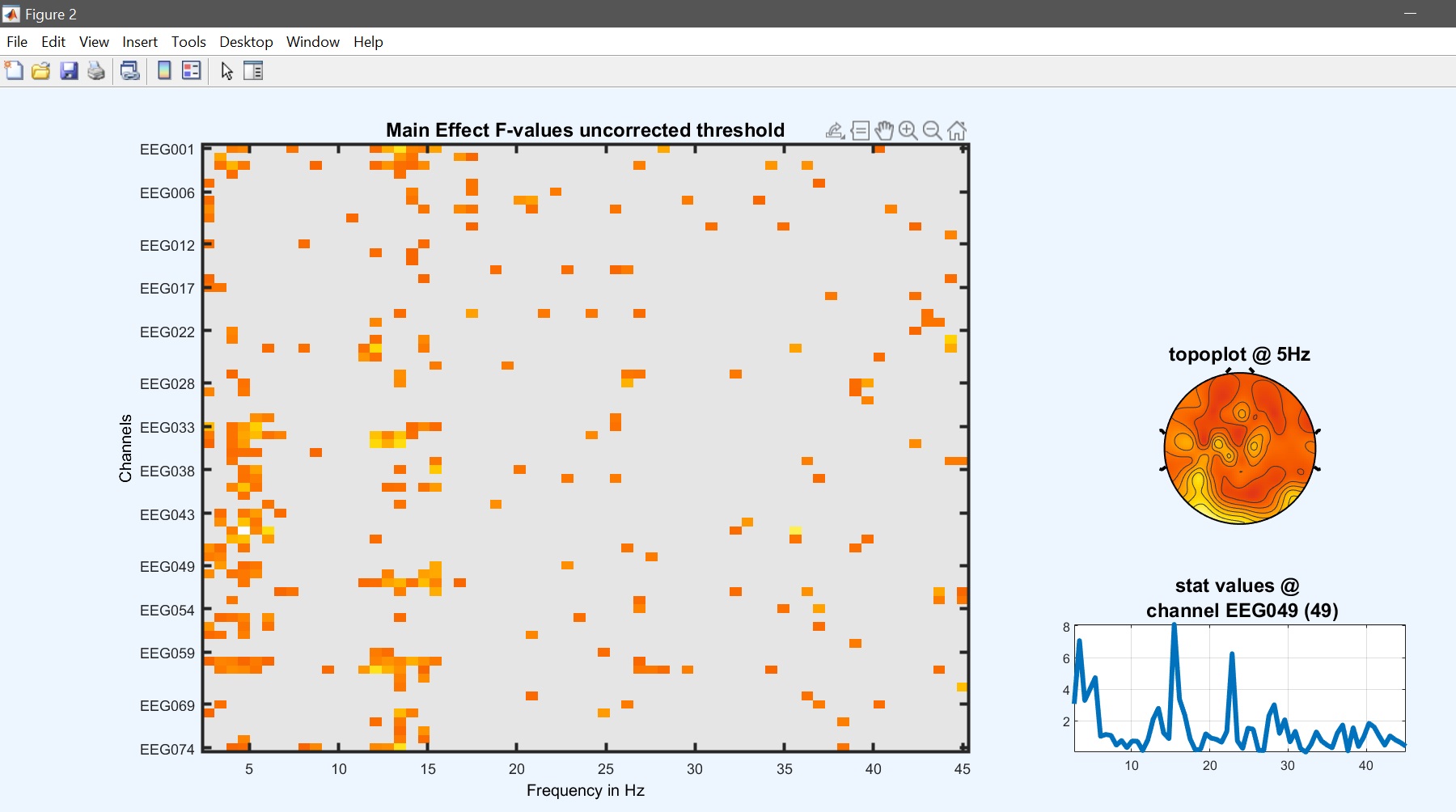
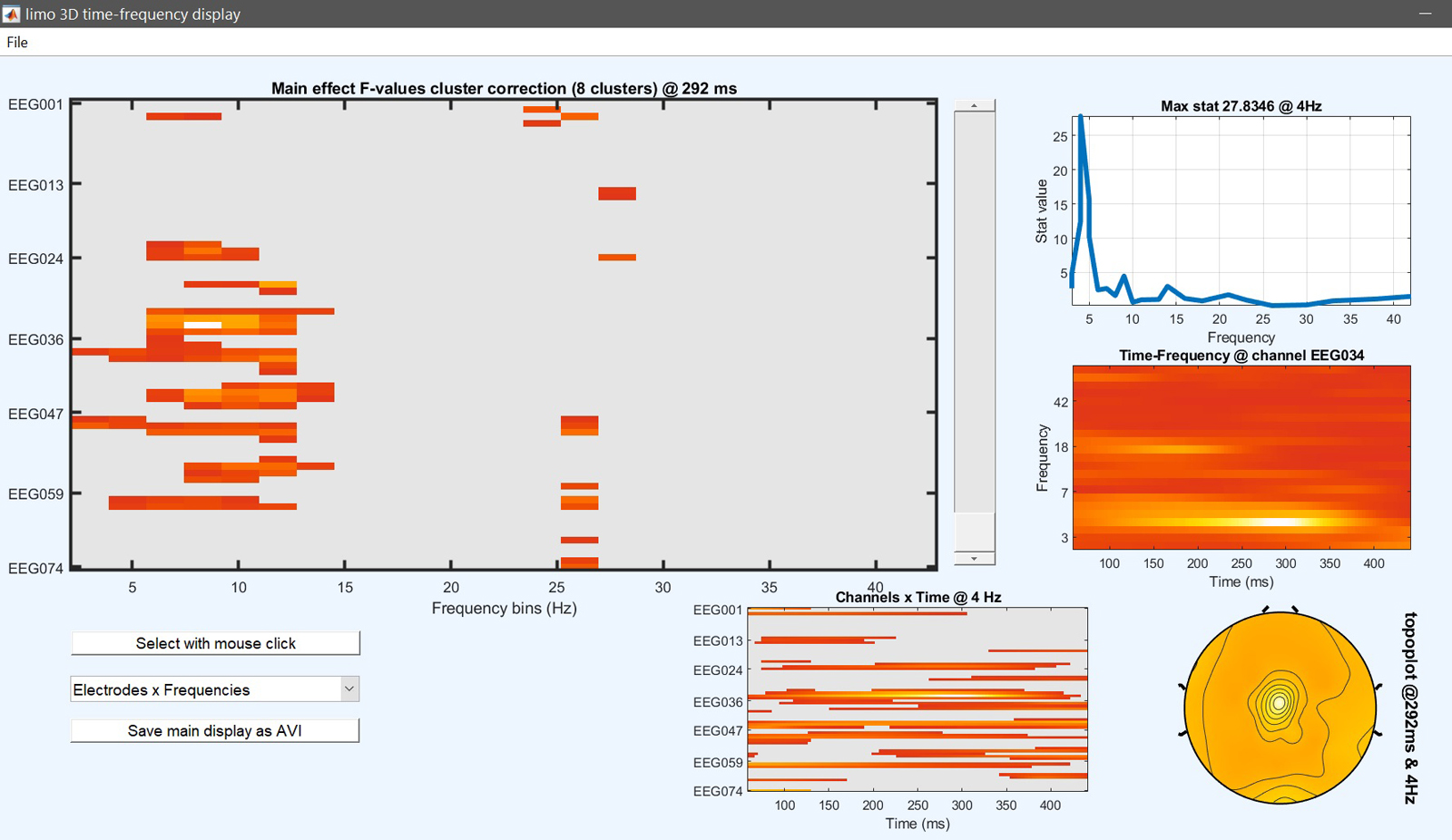
設計行列は、解析を開始するために「はい」にポップアップして応答する必要があります。 その後、結果を確認します()図 22)。 ほとんどの効果は同じですが、結果は異なる 図 15.
{kind=link}
{kind=link}
chanlocs = [STUDY.filepath filesep 'limo_gp_level_chanlocs.mat'];
con1_files = fullfile(STUDY.filepath,['LIMO_' STUDY.filename(1:end-6)],'con_1_files_FaceRepAll_GLM_Channels_Time_WLS.txt');
con2_files = fullfile(STUDY.filepath,['LIMO_' STUDY.filename(1:end-6)],'con_2_files_FaceRepAll_GLM_Channels_Time_WLS.txt');
con3_files = fullfile(STUDY.filepath,['LIMO_' STUDY.filename(1:end-6)],'con_3_files_FaceRepAll_GLM_Channels_Time_WLS.txt');
mkdir([STUDY.filepath filesep '1-way-ANOVA-revised'])
cd([STUDY.filepath filesep '1-way-ANOVA-revised'])
limo_random_select('Repeated Measures ANOVA',chanlocs,'LIMOfiles', {con1_files,con2_files,con3_files},...
'analysis_type','Full scalp analysis','parameters',{[1 1 1]},...
'factor names',{'face'},'type','Channels','nboot',1000,'tfce',0,'skip design check','yes');
limo_eeg(5,pwd) % channel*time imagesc
chanlocs = [STUDY.filepath filesep 'limo_gp_level_chanlocs.mat'];
con1_files = fullfile(STUDY.filepath,['LIMO_' STUDY.filename(1:end-6)],'con_1_files_FaceRepAll_GLM_Channels_Frequency_WLS.txt');
con2_files = fullfile(STUDY.filepath,['LIMO_' STUDY.filename(1:end-6)],'con_2_files_FaceRepAll_GLM_Channels_Frequency_WLS.txt');
con3_files = fullfile(STUDY.filepath,['LIMO_' STUDY.filename(1:end-6)],'con_3_files_FaceRepAll_GLM_Channels_Frequency_WLS.txt');
mkdir([STUDY.filepath filesep '1-way-ANOVA-revised'])
cd([STUDY.filepath filesep '1-way-ANOVA-revised'])
limo_random_select('Repeated Measures ANOVA',chanlocs,'LIMOfiles', {con1_files,con2_files,con3_files},...
'analysis_type','Full scalp analysis','parameters',{[1 1 1]},...
'factor names',{'face'},'type','Channels','nboot',1000,'tfce',0,'skip design check','yes');
limo_eeg(5,pwd) % channel*freq imagesc
chanlocs = [STUDY.filepath filesep 'limo_gp_level_chanlocs.mat'];
con1_files = fullfile(STUDY.filepath,['LIMO_' STUDY.filename(1:end-6)],'con_1_files_FaceRepAll_GLM_Channels_Time-Frequency_WLS.txt');
con2_files = fullfile(STUDY.filepath,['LIMO_' STUDY.filename(1:end-6)],'con_2_files_FaceRepAll_GLM_Channels_Time-Frequency_WLS.txt');
con3_files = fullfile(STUDY.filepath,['LIMO_' STUDY.filename(1:end-6)],'con_3_files_FaceRepAll_GLM_Channels_Time-Frequency_WLS.txt');
mkdir([STUDY.filepath filesep '1-way-ANOVA-revised'])
cd([STUDY.filepath filesep '1-way-ANOVA-revised'])
limo_random_select('Repeated Measures ANOVA',chanlocs,'LIMOfiles', {con1_files,con2_files,con3_files},...
'analysis_type','Full scalp analysis','parameters',{[1 1 1]},...
'factor names',{'face'},'type','Channels','nboot',1000,'tfce',0,'skip design check','yes');
limo_eeg(5,pwd) % channel*time*freq 'imagesc' like
Figure 22. 1-way ANOVA は、第 1 レベルのコントラストに基づく結果をもたらします