ICAコンポーネントのクラスタリング
チュートリアルのこの部分は、 インタラクティブなプリプロセス、クラスター、そしてそれからのダイナミクスを視覚化して下さい ICA(または他の)コンポーネントは1つまたは複数のチュートリアルで動作する
目次
- トピックス
クラスター コンポーネント
概要
全体の電気生理学的結果を比較する 被験者、ほとんどの研究者の通常の慣行が特定されている scalp チャンネル (scalp ) 空間的に等しいデータ)。 実はこれは、 あらゆる物理的電極の空間関係から理想化 (例、Cz、国際10-20システム) 電極のラベリング条約)を基底部の角質領域へ 物理的な場所に応じて、異なる被験者で異なる、 範囲、および特に円錐形の源区域のオリエンテーション、 ‘active’ メトリックサイト(例、Cz) および またはその血糖値 記録された参照チャネル(例えば、鼻、右マストイド、または その他サイト
同等チャンネル(Cz)から記録されたデータ 異なる被験者は、基礎の異なる混合物の活動を要約することができます 同等電極の精度を正確に問わない 。 EEG研究。
ICはICですか?
ICA(特許) しかし、成分を識別するための自然で簡単な方法はありません 別の被験者から1つの(または複数の)コンポーネントを持つ1つの被験者。 ペア 2つの被験者が似ているか、または さまざまな方法で互いに異なるし、異なる程度に – 自分のスカルプマップ、パワースペクトラ、ERP、ERSP、ITCsの違い、または など。 このように、類似性(認知症)対策が多々あります。 活動がグローバルに及ぼすさまざまな方法 コンポーネントペアの類似性を推定するための距離測定。
したがって、被験者間で同等のコンポーネントを識別する問題 EEGLAB 関数と関数の関数は、 柔軟かつ効率的なパフォーマンスとパフォーマンスのためのサポート構造 被験者と条件を横断するコンポーネントのクラスタ評価(参照) 2004 そして、 2005)。 構造解析と実装 EEGLAB は、ICA のライセンスを付与します。 多数の被験者からの1つの条件にわたる分析。 より詳細な情報 データセットに関するさまざまな仮説テストに適用可能 複数の被験者から多くの被験者まで
独立したコンポーネントのクラスタリング(他の多くのデータクラスタリングのような) 単一間違いの解決を持っていません。 コンポーネントの結果を解釈する 従って、原因を保証するクラスタリング。 発見への主張 コンポーネントのクラスタリングからの生理学的事実は、同行する必要があります 思慮深い洞窟と、できれば、統計的なテストの結果によって . . .
ICAコンポーネントクラスタリング
データの読み込みと準備
このチュートリアルでは、 5被験者データセット (450Mb) STUDY作成チュートリアル このデータに関する詳細情報 メニュー項目を選択 ファイル サブメニュー項目を押します 既存の研究をロードする チュートリアル「N400.study」、
STUDYはクラスタリングの準備が整っています。
- ※STUDY* は、研究参加者がデータを閲覧できるようにしました。 STUDY制作 チュートリアル。
- チャンネルの場所を追加しました。 注意: チャンネル すべてのデータセットを同時に編集できます。 メニュー項目 編集 → チャネルの場所).
- キーワード ICA は、 あらゆるデータセットで、
- 。 DIPFIT ダイポールの検索 → ヘッドモデルと設定それから ツール → DIPFIT イヤホンの検索 → オートフィット.
- メニュー項目を使用して定期的に変更を保存しています ファイル → 現在の学習を保存 保存することができます STUDY* リリース テキストボックスにデフォルトファイル名を残します - または新しい入力で ファイル名
コンポーネントを選択
メニュー項目を選択します。 学習 → 学習情報編集 次のインターフェイスがポップアップ表示されます。
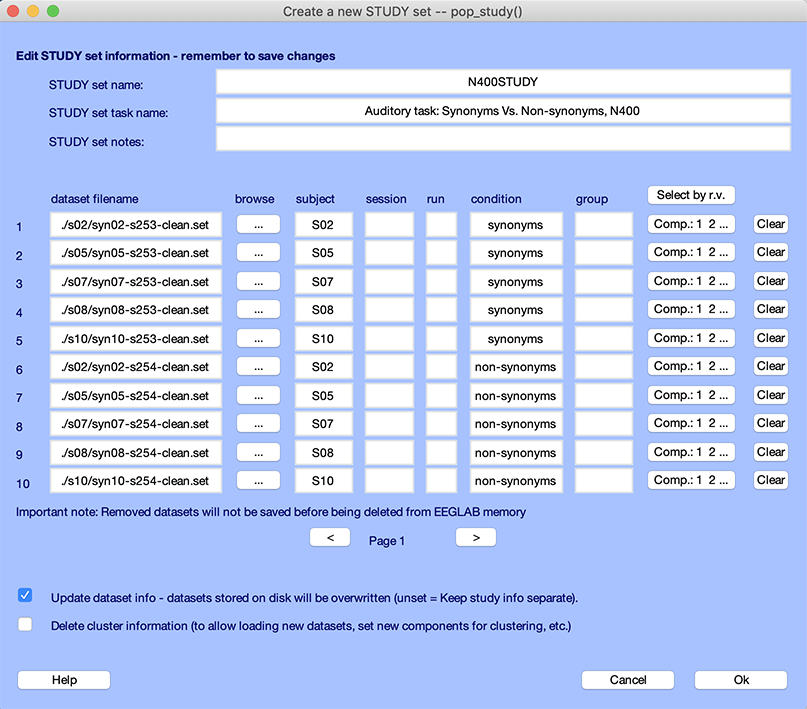
STUDYは、 STUDY作成チュートリアル。 http://www.study.com/ ダイポールモデルの残留期間を設定する 各コンポーネントに関連する。 このボタンを押します。 下記エントリーボックスが表示されます。

このインターフェイスにより、クラスタリングで使用されるコンポーネントを指定できます。 同等のダイポールモデルが残留ダイポールを持っている人だけが コンポーネントのマップの分散、ベストフィットと比較して 頭皮の電極への同等なダイポール モデル投射、より少ないより デフォルト r.v. 15% です。 つまり、ダイポールモデルの残留分散のコンポーネントだけ クラスターに15%未満の料金が加算されます。 これは、 dipolar (または同等の) scalp コンポーネント、1つまたは2つの脳領域からの活動を表す可能性があるもの。 デフォルトの残留差額は15%に設定されます。 つまり、 同じダイポールモデルが15%未満のコンポーネントのみ 残留分散のクラスタリングのために選択されます(参照) この記事について 15% のために のために Okは、 コンポーネントの列がメインの編集で更新される原因 ウィンドウ。
Comp.ボタンは、 上記の残留期限に基づいてクラスタされる各データセットのコンポーネント。 これらを手動で編集することができます。 ご注意 コンポーネント選択を変更(関連するプッシュボタンを押して)、 同じ件名と同じセッション番号を持つすべてのデータセット また、更新されます(これらのデータセットが同じであるように) ICAの要求。
STUDYの編集GUIのOkは変更します。
被験者研究
1つのタスクで収集された連続データ セッション は に 詳細は、Empochsの別々のセットを、 それぞれターゲットおよび非ターゲット。 異なるデータセット 同じセッションで収集される条件は、クラスタリングによって仮定されます 同じICA分解は、すべてのデータからデータに適用されていると仮定されます セッション条件を一度にまとめます。 場合がない場合、データセット 異なる条件から異なる条件に割り当てる必要があります セッション
そのため で で 複数のデータ収集セッションでも収集 より詳しく知る より多くのデータで訓練されたとき分解。 一般的なコンポーネントを持つ 空間マップでは、コンポーネントの挙動を簡単に比較できます。 条件 条件 条件 条件 条件 条件 before で ICA を強制的に処理する 特定のタスク条件に対応する別のデータセット。 その後、特定の条件データセットを抽出します。それらは自動的に
コンポーネントのアクティビティ対策
各データセットのコンポーネントは、 コンポーネントのクラスターは、コンポーネントのクラスターのクラスターのクラスターのクラスターです。 コンポーネントの活用 GUI は GUI に似ています。 詳細は チャンネル可視化チュートリアル.
メニュー項目を選択 研究 → プレコンプトコンポーネント対策。 ERSP/ITCでは、以下の手順に従って、30の周波数と60の時間の速度が優先されます。
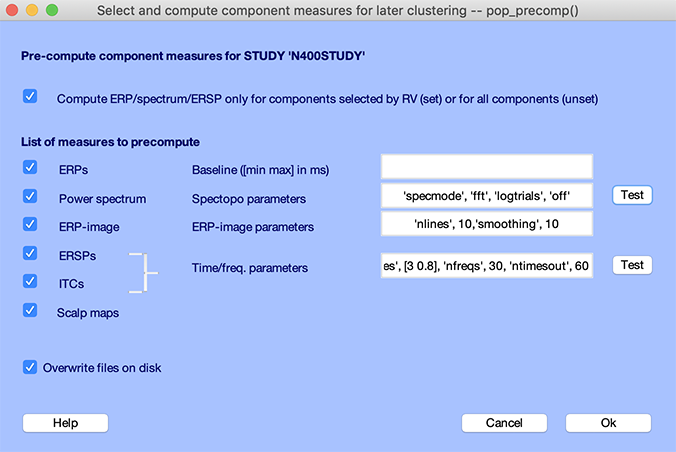
すべての措置を優先するために数分かかる必要があります。
クラスタコンポーネント
EEGLABのクラスタリングメソッドは、以下のクラスタリングメソッドです。 EGLAB は、EeGLAB のプラグインで、Projection メソッドとScalp Correlation method を計測します。
前の行列を作成する
前方インターフェイスの目的は、グローバルな距離を構築することです 部品構成 distance は、通常は、通常は、 farのコンポーネントのマップ、ダイポールモデル、または 活動対策は、ジョイントの空間で互いに異なるものです。 PCAの手順を詳しく説明しています。
条件は構築するために使用されることを意味します このクラスター distance は、 安全GLABの対策:ERP、パワースペクトラム、ERSP、またはITCの スカルプマップ(英語) ダイポールのオプションは、各データセットが読みやすく、入力内容 not の1種類です。
予期しないグラフィックインターフェイスを呼び出します()pop_preclust.m 関数 関数) メニュー項目を使用して PCAの勉強クラスタリング(オリジナル) → ビルド前方配列 GUI と関数 以下は、 各コンポーネントのクラスター distance のクラスター distance
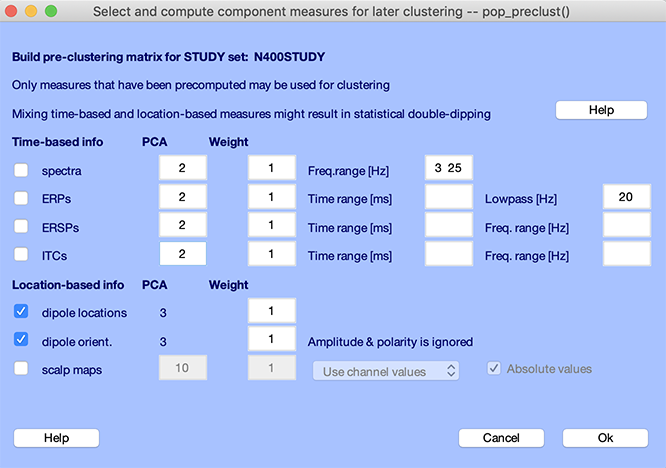
左側のチェックボックスは2番目のセクションで pop_preclust.m 関数 上記のインターフェイスは選択を可能にします cluster コンポーネントのセキュリティ対策 測定 構築されたクラスタリングを実行します。
ゴール N次元クラスターを計算する 各コンポーネントの構成要素 cluster position 各コンポーネント distance は、 N次元空間でクラスタリングを行います。PCAで次元削減されたERP、ERSPなどの特徴量が使用されます。
クラスター位置ベクトルでは、各成分の等価ダイポール位置が3次元(x, y, z)の値で表されます。続く2つの値は、たとえば第1条件ERPの主要な2つの主成分を表し、その次の2つの値は第2条件ERPの主要な2つの主成分を表す、といった形になります。時間/周波数のスペクトル摂動画像を計算している場合、約3000個に及ぶすべての時間周波数値をそのまま使うことはできません。この場合も、Dim.列の入力を使って次元数を2または3などに減らしてください。
次元の正規化
選択した位置および活動測定値の主成分次元は、測定値間で尺度をそろえるためにnormalizeできます。これはnorm列のチェックボックスをオンにして行います。この正規化では、その測定値の第1主成分の標準偏差で、すべての主成分の測定データを割ります。
他の測定値に対する相対的な重みも指定できます。たとえば2つの測定値AとBを使い、AにBの2倍の重みを与えたい場合は、両方の測定値を正規化し、Aに2、Bに1を入力します。測定値Aのほうが測定値Bより関連情報を多く含むと考える場合は、AにBより多いPCA次元数を割り当てることもできます。
コンポーネント対策
以下の測定値は、計算済みであればクラスタリングやクラスター可視化に使用できます。まず、時間に基づく測定値です。
-
Spectra: 最初のチェックボックスでは、各条件の対数平均パワースペクトルを事前クラスタリング測定値に含められます。チェックボックスをクリックすると、パワースペクトルのパラメータを入力できます。この場合、Hz単位の周波数範囲[lo hi]が必要です。クラスタリング目的では(表示目的ではありません)、各被験者について、選択した全周波数で平均したスペクトル値を選択成分すべてから差し引き、さらに各周波数で選択成分にわたって平均したスペクトル値をすべての成分から差し引きます。これは、被験者によってEEGパワーが大きく異なるためです。対数平均を差し引かないと、クラスターが1人の被験者だけ、または特定の種類の被験者だけの成分で構成される可能性があります。
-
ERPs: 2番目のチェックボックスでは、各条件の平均ERPを計算します。ここでは、ms単位のERP潜時範囲[lo hi]が必要です。
-
ERSPs and/or ITCs: 続く2つのチェックボックスでは、イベント関連スペクトルパワー変化(ERSP)とイベント関連位相一貫性(ITC)として、イベント関連スペクトル摂動情報を各条件に含められます。
次に、位置に基づく測定値です。
-
Dipole locations: 3番目のチェックボックスでは、コンポーネントの等価ダイポール位置を事前クラスタリング処理に含められます。ダイポール位置は[x y z]で示され、自動的に3次元になります。ダイポール向きでクラスタリングすることも可能です。前述のとおり、各コンポーネントおよびデータセットについて等価ダイポールモデルが事前に計算されている必要があります。1つのコンポーネントが2つの対称ダイポールでモデル化されている場合、pop_preclust.m 関数はクラスタリングに2つのダイポールの平均位置を使用します。
-
Scalp maps: 最後のチェックボックスでは、コンポーネントのスカルプマップ情報をクラスター位置に含められます。生のコンポーネントマップ値、ラプラシアン、または空間勾配を使うことができます。主要成分についてはラプラシアンスカルプマップである程度よい結果が得られていますが、スカルプマップより等価ダイポール位置を使うほうが妥当な理由があります。絶対マップ値だけを使うかどうかも選択できます。絶対値を使う利点は、任意に決まるコンポーネントマップの極性に依存しないことです。情報が冗長なため、ダイポール情報とスカルプマップ情報を同時に使うことは推奨しません。
上に示したpop_preclust.m 関数のインターフェイスでは、ダイポールのチェックボックスだけを選択し、その他はデフォルトパラメータのままにします(ウィンドウ上部のダイポール残差分散フィルタを含む)。総次元数は、選択したすべての測定値の次元数の合計です(この例では3+3=6)。特にコンポーネント数が限られている場合、クラスタリングアルゴリズムは10次元を超えると十分に動作しないことがあります。この例では、コンポーネント数(残差分散しきい値に基づいて選択された151個)に対して次元数(6)は許容範囲です。
プレス Ok.
クラスタリングアルゴリズムの適用
pop_clust.mのクラスター関数インターフェイスは、下図のようにStudy → PCA clustering (original) → Cluster componentsメニュー項目から呼び出せます。
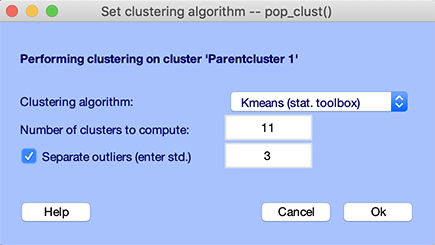
利用できるアルゴリズムには、kmeans、neural network、affinityなどがあります。
kmeansにはMATLAB Statistics Toolboxが必要です。neural networkクラスタリングはMATLAB Neural Network Toolboxの関数を使います。MATLAB Statistics Toolboxを必要としないkmeansのバージョンも利用できます。affinityクラスタリングには追加ツールボックスは不要です。まずクラスター数を指定しなくてよいaffinityクラスタリングを使い、結果が十分でない場合にkmeansを試すことを推奨します。
kmeansでは、デフォルトのクラスター数は、各クラスターに被験者ごと平均1成分が含まれるように設定されます。たとえば、残差分散しきい値に基づいて被験者ごと約20個の成分が選択され、STUDYに10名の被験者が含まれる場合、クラスター数は20に設定され、各クラスターには平均10成分が含まれます。この例では被験者数が少ないため、クラスターあたりの成分数を増やす目的で11を入力します。
kmeans.mアルゴリズムには、outlier成分を別クラスターに分けるオプションがあります。外れ値成分は、任意のクラスター重心から指定した標準偏差数(デフォルトは3)より遠い成分として定義されます。このオプションを有効にするには、左上のチェックボックスをクリックします。検出された外れ値成分は、指定されたOutliersクラスター(Cluster 2)に配置されます。
Okを押します。以降のセクションで説明するクラスター編集インターフェイスが自動的に表示されます。
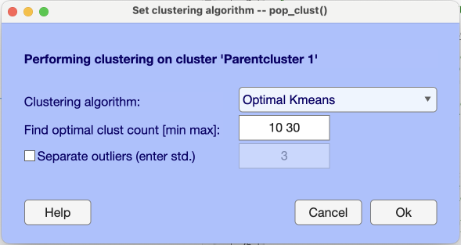
Optimal Kmeansクラスタリング
最近、pop_clust関数にOptimal Kmeansアルゴリズムが追加されました。この機能を使うと、データに適したクラスター数を探索できます。利用するには、MATLAB Statistics and Machine Learning Toolboxがインストールされている必要があります。
この機能を使うには、Clustering algorithmドロップダウンメニューからOptimal Kmeansを選択します。次に、テストするクラスター数の範囲を入力します(下のスクリーンショットでは最小値を10、最大値を30に設定しています)。アルゴリズムは指定範囲の各クラスター数でクラスタリングを試し、silhouetteスコアに基づいて最適なクラスター数を選びます。silhouetteスコアは、あるオブジェクトが他のクラスターと比べて自分のクラスターにどれだけ似ているかを測る指標です。最適なクラスター数は、silhouetteスコアが最大になる数です。silhouetteスコアの詳細はMATLABドキュメントを参照してください。
推奨するクラスター数: 上で説明した推定クラスター数の考え方に従い、探索範囲の下限は、被験者ごとの平均コンポーネント数の半分に設定することを推奨します。たとえば、被験者ごとに20個のコンポーネントがある場合、下限は10にします。同様に、上限は被験者ごとの平均コンポーネント数の1.5倍に設定します。被験者ごとに20個のコンポーネントがある場合、上限は30です。返されたクラスター数が下限または上限に張り付く場合は、範囲を広げることを検討してください。また、外れ値を分離するオプションを使用することも強く推奨します。
他のクラスタリング方法
EEGLABで成分をクラスタリングする主な方法は、このチュートリアルで説明しているPCA clustering methodです。その他の方法として、以下のEEGLABプラグインで利用できるMeasure Projection methodとScalp Correlation methodがあります。
測定プロジェクションプラグインでクラスターを探す
Measure Projectionでは、各ICペアについて、等価ダイポールを除くIC測定値(ERP、ERSPなど)を比較し、それらの非類似度を掛け合わせて、結合されたペアワイズ非類似度行列を作成します。この行列は正規化および重み付けされ、正規化・重み付けされたIC等価ダイポール距離行列に加算されます。最終的な非類似度行列は、affinity clustering法でクラスタリングされます。詳細はプラグインのGitHubリポジトリを参照してください。
Corrmapプラグインでクラスターを探す
Corrmapは、頭皮トポグラフィの相関に基づいて成分をクラスタリングするEEGLABプラグインです。このプラグインのドキュメントは、Stefan DebenerのウェブページおよびプラグインのGitHubリポジトリで確認できます。
コンポーネントクラスターの可視化
pop_clustedit.mのクラスター編集関数は、Study → Edit → plot clustersメニュー項目から呼び出せます。次のウィンドウが開きます。
前のセクションで使用したStudy → PCA clustering (original) → Cluster componentsメニュー項目も、クラスタリング完了後にこのウィンドウを自動的に呼び出します。
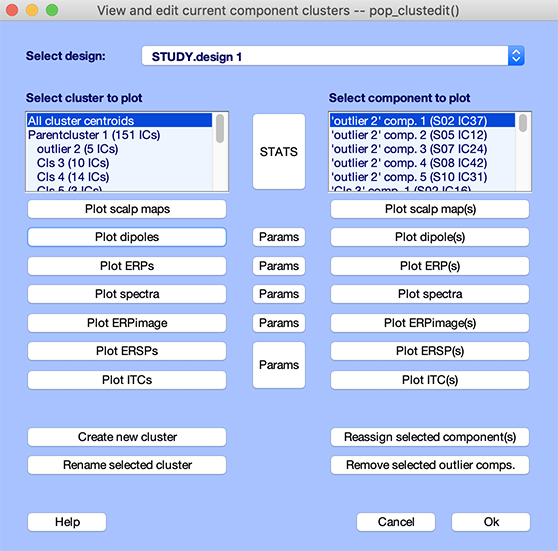
サンプルN400 STUDYの305成分のうち、151成分ではダイポールモデルの残差分散が15%未満でした。その他の成分はクラスタリングから除外されました。選択された成分は、ダイポール位置に基づいて11個の成分クラスターと1個の外れ値クラスターに分類されました。
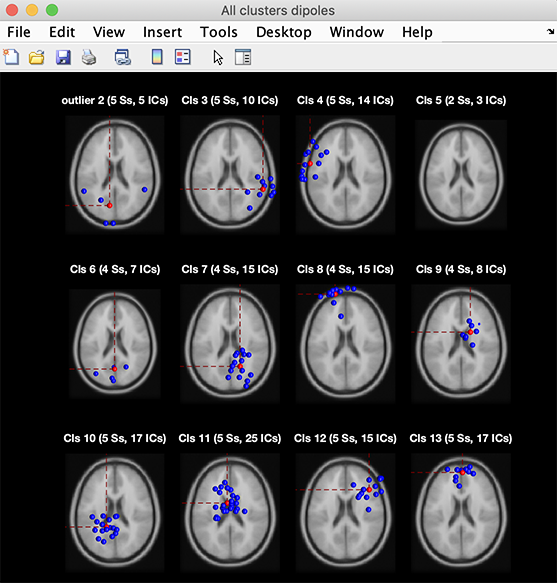
左上のリストからクラスターを選択すると、右上のテキストボックスにそのクラスターの成分リストが表示されます。左側リストのAll cluster centroidsオプションを選択すると、ParentClusterを除くすべてのクラスターの結果を表示できます。続いてプロットオプションのいずれかを選択すると、すべてのクラスター重心が1つの図に表示されます。すべてのクラスターのダイポール位置を確認するには、左列のPlot dipolesボタンを押します。プロットビューアが開き、すべてのクラスター成分のダイポール(青)と、クラスター平均ダイポール位置(赤)が表示されます。成分が、異なる位置を持つダイポール群としてクラスタリングされていることがわかります。
Plot scalp mapsオプションを押すと、クラスターのスカルプマップも確認できます。次の図が表示されます。
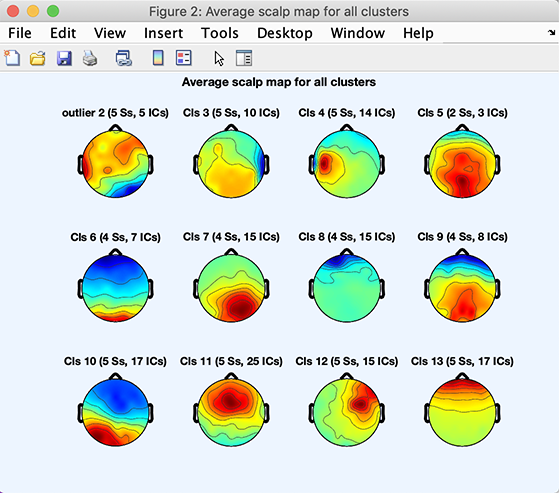
kmeansアルゴリズムは成分のランダムな初期割り当てから始まるため、実際のクラスターはわずかに異なる場合があります。
平均クラスター・スカルプマップ(またはスカルプマップ重心)を計算するときは、まず各成分マップの極性を、クラスター平均と正に相関するように調整します(成分マップには絶対的な極性がないことを思い出してください)。次にマップ分散をそろえ、最後に正規化された平均を計算します。
クラスター内の個々の成分スカルプマップを見るには、左列で対象クラスターを選択します(上図の例ではCluster 6)。次に、右列のPlot scalp mapsオプションを押します。次の図が表示されます。実際のデータでは、クラスター番号が異なる場合があります。
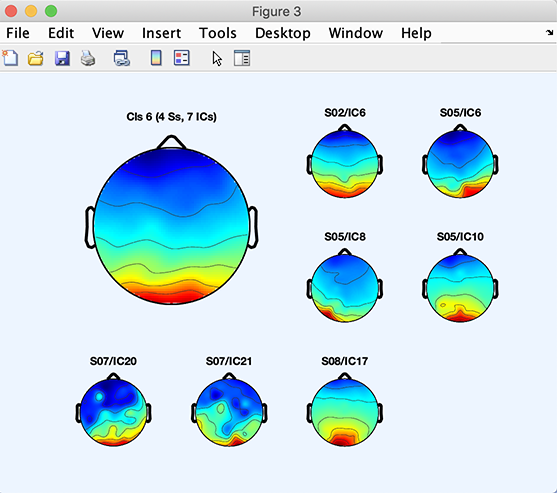
ここでSO2 IC6は「被験者SO2の独立成分6」を意味します。
いずれかのデータセットでチャネルが欠損していても、クラスターのスカルプマップのクラスタリングや可視化には影響しません。成分スカルプマップはtoporeplot.m関数によって補間されるため、STUDYデータセットを共通の「常にクリーンな」チャネル部分集合に制限したり、個別データセットでmissing channel補間を実行したりする必要はありません。
右列で成分を選択し、Plot scalp mapsを押すことで、クラスター内の個別成分のスカルプマップもプロットできます(図は示していません)。
このクラスターのダイポールをプロットすることもできます。左列または右列のPlot dipolesボタンを押します。次の画像が表示されます。
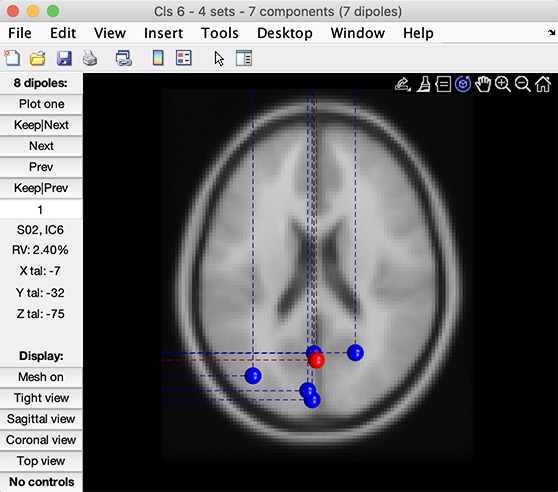
ダイポールを1つずつスクロールし、3Dプロットを回転したり、3つの基本ビュー(左下のボタン)から選択したりできます。プロットされたダイポールに関する情報は、左中央のサイドバーに表示されます(上図を参照)。
このクラスターについて、個別成分のスペクトルと合わせてクラスターのスペクトルもプロットしてみます。右列のPlot spectraボタンをクリックします。
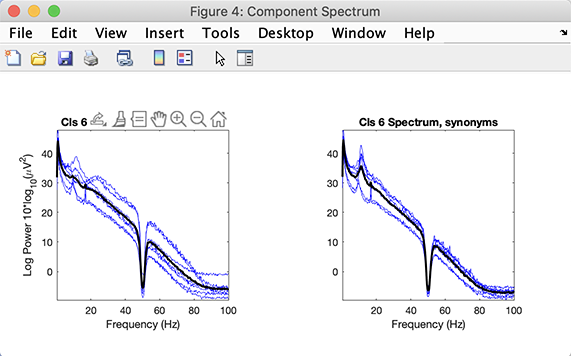
このクラスターのすべての成分に、明瞭な10 Hzピークが見えます。最後に、このSTUDYの2条件についてERPをプロットします。中央列でPlot ERPsボタンの横にあるParamsボタンをクリックし、下図のように時間範囲を-200 msから1000 msに変更します。最初の独立変数を同じプロット上に表示するチェックボックスを選択し、Okを押します。

次に、右列のPlot ERPsボタンをクリックします。次のウィンドウが表示されます。
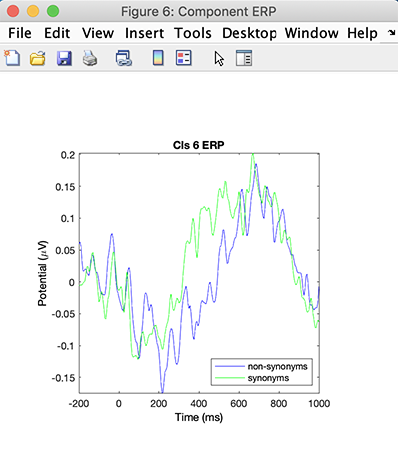
ここでは、Cluster 6が中心後頭部のアルファ活動の一部を説明しています。活動スペクトルに強い10 Hzピークがある点に注目してください。クラスターERPは非常に遅い(1 Hz)パターンを示しています。遅波活動における条件間の見かけの潜時シフトが有意かどうかは、統計解析が必要です。
活動特徴から成分クラスターの性質を素早く見分けるには経験が必要です。詳細はICA分解チュートリアルを参照してください。
クラスターの編集
クラスタリング結果は、Study → Edit/plot clustersメニュー項目から呼び出すクラスター表示/編集ウィンドウで手動更新することもできます。これらの編集オプションにより、クラスタリング結果を柔軟に調整できます。成分を別のクラスターへ再割り当てしたり、新しいクラスターを作成したり、クラスターからoutlier成分を除外したりできます。pop_clustedit.m GUIで変更した後にそれらを取り消したい場合は、Cancelボタンを押すとSTUDYの変更は破棄されます。
クラスターを編集する4つのボタンを以下に説明します。
-
Renaming a cluster. Rename selected clusterオプションを使うと、任意のクラスターにわかりやすい名前を付けられます。このボタンを押すと、選択したクラスターの新しい名前を入力するポップアップウィンドウが開きます。たとえば、まばたきを説明する成分を含むクラスターだと判断した場合は、”Blinks”と名前を付けることができます。
-
Removing selected outlier components manually. outlier成分は手動でクラスターから除外できます。このオプションでは、クラスター平均からの距離とは関係なく、外れ値と思われる成分を選択解除できます。手動で成分を除外するには、まず左のリストから対象クラスターを選び、次に右側の成分リストから除外したいoutlier成分を選択し、Remove selected outlier compsボタンを押します。確認ウィンドウが表示されます。
-
Creating a new cluster. 新しい空のクラスターを作成するには、Create new clusterオプションを押します。新しいクラスター名を尋ねるポップアップウィンドウが開きます。名前を入力しない場合、デフォルト名は’Cls #‘になります。ここで’#‘は次に利用可能なクラスター番号です。変更を反映するには、ポップアップウィンドウのOkボタンを押します。新しい空のクラスターは、編集/表示クラスターウィンドウ左側のリストに追加されます。
-
Reassigning components to clusters. 2つのクラスター間で成分を移動するには、まず左のリストから移動元クラスターを選択し、右の成分リストから対象成分を選択して、Reassign selected component(s)ボタンを押します。利用可能なクラスターのリストから移動先クラスターを選択します。
さらなるコンポーネントクラスタリングの検討事項
ICAクラスター内に同じ被験者の複数成分がある場合
ICAクラスターをプロットする際、EEGLABではデフォルトで、同じ被験者の複数成分が1つのクラスターに含まれることを許可しています。これは統計解析を行う場合に問題になることがあります。
同じ被験者から複数の成分を含めると、一般的な被験者集団について推論しているのではなく、研究対象となっている特定の被験者の成分について推論していることになります。問題の大きさは、被験者数に対して各被験者から何個の成分が入っているかによって決まります。
たとえば、クラスター内に被験者あたり平均1成分があり(0成分の被験者もいれば2成分の被験者もいる)、被験者数が200名であれば、一般的な被験者集団への推論を可能にする元の帰無仮説はほぼ保たれます。しかし、被験者が10名で、あるクラスターに同一被験者の成分が10個含まれている場合は、そうではありません。
一般に、ICAクラスター内に同じ被験者から複数成分が含まれることが問題になる場合、統計的な妥協を避けるために、各クラスターで被験者あたり最大1成分を使うことを推奨します。これは、EEGLAB Corrmapプラグインを使ってデータをクラスタリングする場合に可能です。代替として、クラスター内の成分を手動で削除することもできます。
クラスタリングに使うSTUDYデザインの選択
ICA成分を事前クラスタリングするとき、現在のSTUDYデザインが考慮されます。
たとえば、被験者ごとに2条件があり、両条件が同じICA成分セットを共有している場合、事前クラスタリング中にクラスタリングで使う成分間距離測定値を計算する際、両条件のデータ測定値が連結されます。平均パワースペクトルを使って成分をクラスタリングする場合、各成分について50個のスペクトル値(各周波数に1つ)を使う代わりに、事前クラスタリングでは100個の値(条件ごとに50周波数のセットを2つ)が順に配置されます。EEGLABでは、すべてのSTUDYデータセットを含まないSTUDYデザインを使って成分をクラスタリングすることはできません。なお、スカルプトポグラフィや等価ダイポールなどの解剖学的な成分情報だけを使い、他の測定値を使わずにクラスタリングする場合、STUDYデザインはクラスタリング解に影響しません。
したがって、事前クラスタリングには、できるだけ単純なSTUDYデザインを使うことを推奨します。多くの場合、それは実験にとって最も自然なデザインです。クラスタリング後は、すべてのICA成分がクラスタリングに含まれているため、ICAクラスターはすべての条件およびSTUDYデザインで一定です。したがって、成分がいったんクラスタリングされれば、任意のSTUDYデザインについてクラスター活動を比較できます。
異なる条件におけるクラスター活動の比較
ICA成分がクラスタリングされると、任意のSTUDYデザインを使って条件間の差を計算できます。異なるデザインを選択するたびに、ICA成分はクラスタリング解に従い、そのデザイン内の条件へ割り当てられます。たとえば、被験者ごとにICA分解が1つだけで、2x1デザイン(2条件、1被験者群、1セッションで収集)の場合、両条件は同じ成分を共有します。
条件間でICA成分の活動を比較することは、異なるデータチャネルの活動を比較することに似ています。条件間で成分クラスターの活動を比較することは、被験者間で特定チャネルの活動を比較することと似ていると考えられます。ICA成分と電極チャネルはどちらも空間フィルタです。各データチャネルは、ある頭皮電極に到達する電位と参照電極(または参照電極群に到達する電位の平均)に到達する電位との差です。各ICA成分は、各電極に到達する信号の重み付き和または差です。このとき負の重みを持つ電極信号は、参照チャネルの役割を果たしていると言えます。ただし、このチャネルの組み合わせは通常、成分ごとに異なります。
2つの被験者群の成分活動を比較するSTUDYデザインでは、計算される測定値の差は、各クラスター内の各グループの成分間の差になります。
自分のデータで試す
チュートリアル例を配布しやすくするため、ここでは少数の被験者と少数のクラスターだけを使っています。そのため、一貫していて性質を識別しやすい成分クラスターが見つからない場合があります。15名から30名以上の被験者のデータをクラスタリングした場合、より満足できる結果が得られています。
サンプルデータでこのチュートリアルを終えた後は、性質をよく理解している、より大きなデータセット群でSTUDYを作成することを推奨します。そのうえで、そのSTUDYの成分を複数の方法でクラスタリングしてみてください。生成された成分クラスターの一貫性と性質を慎重に検討し、どのクラスタリング方法が研究目的に適したクラスターを生成するかを判断してください。