EEGLABの解析
これらの関数は直接ユーザーによって呼び出されます。 これらの関数を簡潔に記述します。 MATLAB は、現在、 std_ は、 STUDY または EEG は、 チャネルまたはクラスターに直接信号処理および/またはプロットを実行 活動内容 関係なく、記述するチュートリアルの部分で文書を調べるのは自由です STUDYについて.
目次
- トピックス
STUDYについて
STUDY は、 pop_study.m で多くの研究を造る必要がある場合や、 STUDY に参加する
*STUDY構造は、 STUDYチェック機能(STUDYチェック機能)std_checkset.m は、) 複数のチェックを実行して、それが表しているデータセットと互換性を保つことができます。 だからこの機能 変更を解除する可能性があります(コマンドラインで警告が発行されます)。 データセットを自分で変更して達成できることが多い STUDYをフォローする 構造。
MATLABは、 GUI-equi同等主義者 std_editset.m は “5subjects” の使い方 詳しくはこちら) それからあなたが不圧縮したフォルダへのパスを変更します。 このページで使用されるコードスニペットは、 ._script.m 学習
[STUDY ALLEEG] = std_editset( STUDY, [], 'name','N400STUDY',...
'task', 'Auditory task: Synonyms Vs. Non-synonyms, N400',...
'filename', 'N400empty.study','filepath', './',...
'commands', { ...
{ 'index' 1 'load' 'S02/syn02-S253-clean.set' 'subject' 'S02' 'condition' 'synonyms' }, ...
{ 'index' 2 'load' 'S05/syn05-S253-clean.set' 'subject' 'S05' 'condition' 'synonyms' }, ...
{ 'index' 3 'load' 'S07/syn07-S253-clean.set' 'subject' 'S07' 'condition' 'synonyms' }, ...
{ 'index' 4 'load' 'S08/syn08-S253-clean.set' 'subject' 'S08' 'condition' 'synonyms' }, ...
{ 'index' 5 'load' 'S10/syn10-S253-clean.set' 'subject' 'S10' 'condition' 'synonyms' }, ...
{ 'index' 6 'load' 'S02/syn02-S254-clean.set' 'subject' 'S02' 'condition' 'non-synonyms' }, ...
{ 'index' 7 'load' 'S05/syn05-S254-clean.set' 'subject' 'S05' 'condition' 'non-synonyms' }, ...
{ 'index' 8 'load' 'S07/syn07-S254-clean.set' 'subject' 'S07' 'condition' 'non-synonyms' }, ...
{ 'index' 9 'load' 'S08/syn08-S254-clean.set' 'subject' 'S08' 'condition' 'non-synonyms' }, ...
{ 'index' 10 'load' 'S10/syn10-S254-clean.set' 'subject' 'S10' 'condition' 'non-synonyms' }, ...
{ 'dipselect' 0.15 } });
上記では、コマンドの各行がデータセットをロードします。
最後の行 同等のダイポールモデルが15%未満のコンポーネントを選択 コンポーネントのスカルプマップからの残留分散。 詳細は std_editset* を参照してください。
データセットへのパスについて 上のコードは相対パスです。 その後、同じコードを実行する snippet,MATLABの現在のディレクトリ,データセットは、現在に至る。
STUDY 構造 (または STUDY) は、 STUDY 構造と対応 ALLEEG は、 MATLAB ワークスペースは
タイピング >> MATLABの STUDY は、
>> STUDY =
struct with fields:
history: 'STUDY = []; [STUDY ALLEEG] = std_checkset(STUDY, ALLEEG);'
datasetinfo: [1×10 struct]
name: 'N400STUDY'
task: 'Auditory task: Synonyms Vs. Non-synonyms, N400'
notes: ''
filename: 'N400empty.study'
filepath: '.'
subject: {'S02' 'S05' 'S07' 'S08' 'S10'}
group: {}
session: []
condition: {'non-synonyms' 'synonyms'}
etc: [1×1 struct]
cache: []
preclust: [1×1 struct]
cluster: [1×1 struct]
changrp: [1×61 struct]
design: [1×1 struct]
currentdesign: 1
saved: 'yes'
conditionsは必須項目です。(synonymsとnon-synonyms)は、EEGLABは2つの条件を構成しています。 std_makedesign.m の使い方 で EEGLABのデザイナーがデザインを手がける eegh.m 関数)。 デザインを作成するためのイベント情報を追加する場合は、チュートリアルのセクションを参照してください。 グループ分析のためのイベント情報の追加.
チャネル対策の計算とプロット
コンピューティング対策
関数を使う pop_precomp.m 関数 (関数を呼び出す) std_precomp.m は、 チャネル対策を優先します。 例えば、 次のコードは、コンピューティング用のグラフィックユーザーインターフェイスを呼び出します チャネルにおける対策
>> [STUDY ALLEEG] = pop_precomp(STUDY, ALLEEG);
コマンドラインから優先措置を使用する場合は、以下のコードスニペットがすべてのデータセットのERP計算を補います。
>> [STUDY ALLEEG] = std_precomp(STUDY, ALLEEG, 'channels', 'erp', 'on', 'erpparams', {'rmbase' [-200 0]});
プロット対策
同じ機能を使って結果をプロットすることができます。 コンポーネントクラスタ用 注文する ‘Oz’, 試す.
>> STUDY = std_erpplot(STUDY, ALLEEG, 'channels', {'Oz'});
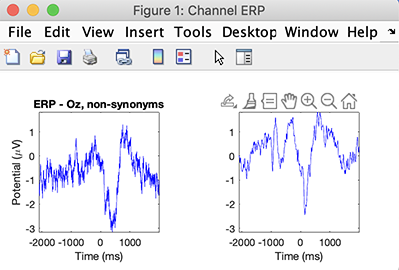
出力変数をヘルプメッセージに記述したように追加することでデータを取得できます。 std_erpplot.m は、 関数は std_plotcurve の 関数をリプロットします。
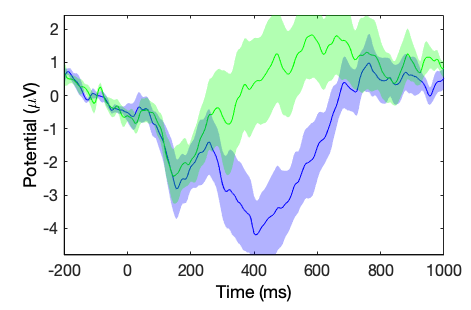
[STUDY erpdata erptimes] = std_erpplot(STUDY, ALLEEG, 'channels', {'Oz'}, 'timerange', [-200 1000]);
std_plotcurve(erptimes, erpdata, 'plotconditions', 'together', 'plotstderr', 'on', 'figure', 'on', 'filter', 30);
上記のように、 std_plotcurve.m の使い方 関数は付加的な持っています 標準的な間違いをプロットする変数はから利用できません EEGLABの出力 std_erpplot.m は、 また、追加で制御することもできます ネイティブパラメータ std_erpplot.m は、 そして、 pop_erpparams.m 関数.
たとえば、追加通知 timerange は、レイテンシの範囲で設定できます。 200〜1000ms。
グラフィックインターフェイスをプロットするチャンネルから他のコマンドを試し、履歴で返されたものを見る (eegh.m 経由)。
その後の処理のための計算された対策の取得
STUDYプロット、プロット結果がわかる STUDY プロット関数を 実行 すると、 MATLAB は、STUDY は、 この関数の助けを見てみましょう。 通常は追加可能です 追加パラメータ。
例:EEGLAB 次の 次の
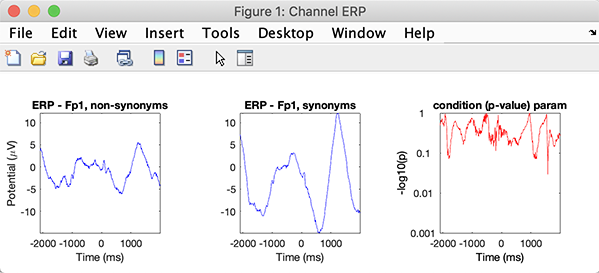
>> STUDY = std_erpplot(STUDY,ALLEEG,'channels',{ 'FP1'});
取得結果は2つで、EarPデータとERPの2つを出力します。 時間値、続くように:
>> [STUDY erpdata erptimes] = std_erpplot(STUDY,ALLEEG,'channels',{ 'FP1'}, 'noplot', 'on');
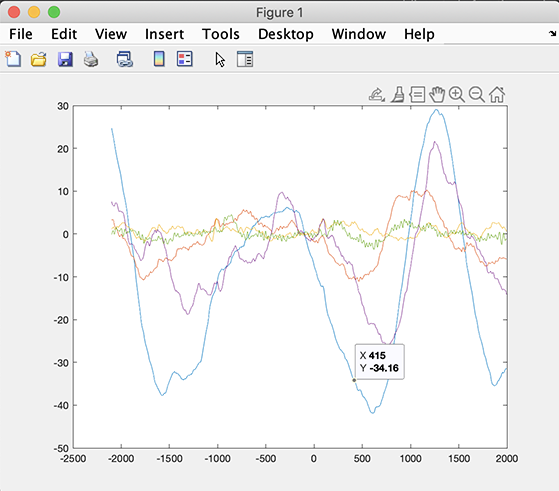
erpdata 開発者がERPデータを取得しています。 また、STUDY がデザインするので、 第2弾の写実体をデザインする STUDYの細胞(synonyms)。
>> figure; plot(erptimes, erpdata{2});
小さなスクリプトは、小さな研究で時間頻度分解を計算します。 また、データセットで時間の頻度分解を比較します STUDYをクリアする
% Compute newtimef on first dataset for channel 1
options = {'freqscale', 'linear', 'freqs', [3 25], 'nfreqs', 20, 'ntimesout', 60, 'padratio', 1,'winsize',64,'baseline', 0};
TMPEEG = eeg_checkset(ALLEEG(1), 'loaddata');
figure; X = pop_newtimef( TMPEEG, 1, 1, [TMPEEG.xmin TMPEEG.xmax]*1000, [3 0.8] , 'topovec', 1, 'elocs', TMPEEG.chanlocs, 'chaninfo', TMPEEG.chaninfo, 'plotphase', 'off', options{:},'title',TMPEEG.setname, 'erspmax ',6.6);
% Compute newtimef for all datasets and plot first channel of first dataset
[STUDY, ALLEEG] = std_precomp(STUDY, ALLEEG, 'channels','recompute','on','ersp','on','erspparams',{'cycles' [3 0.8] 'parallel' 'on' options{:} },'itc','on');
STUDY = std_erspplot(STUDY,ALLEEG,'channels',{TMPEEG.chanlocs(1).labels}, 'subject', 'S02', 'design', 1 );
以下のスクリプトの結果(プロットをクリックしてカラースケールを調整するサイドパネルを削除します)。 同じ機能で結果が同じであることは驚くべきことではありません どちらのケースでも使われています。
|  |
統計結果の取得
統計を計算できる全てのプロット機能は、 出力中の統計配列。 最初に統計を有効にする必要があります グラフィックインターフェイスから、またはコマンドラインコールを使用する。
条件統計を計算するインスタンスの場合、タイプ:
>> STUDY = pop_statparams(STUDY, 'condstats', 'on');
それから、与えられたチャネルのために、タイプして下さい:
>> [STUDY erpdata erptimes pgroup pcond pinter] = std_erpplot(STUDY,ALLEEG,'channels',{ 'FP1'});
今、タイピング:
>> pcond
pcond =
[820x1]
配列は、毎回820 p 値、1つを呼び出します。
返される統計の種類は、パラメータに依存することに注意してください。 ERP パラメータ グラフィック インターフェイス で 選択します。 選択された permutation 値、surrogate オブジェクト p 値 データが返されます。
pgroup と pinter の配列は、グループとグループを構成します。 ANOVAの利用規約 あります。
その他の機能など std_specplot.m は、, std_erspplot.m は、と std_itcplot.m は、 アクション 同様の方法(詳細については、関数ヘルプメッセージを参照してください)。 より多くの制御のために、また直接呼ぶことができます注意して下さい スタコンド。 m 点 は、関数、erpdata を セル配列 に あります。 入力。 ヘルプメッセージを見る スタコンド。 m 点 この件名にもっと役立つ機能(このページの最後に例も参照)。
他のソフトウェアパッケージで処理する結果を保存する
SPSS、Statistica、Stata、R、SAS、Excelの処理 STUDYを飲む MATLAB は、MATLAB のライセンスをそのまま使用しています。 以下は、 デフォルトではコンマ区の値を格納します。
array = erpdata{1}; % or array = rand(100,200);
dlmwrite('matlabarray1.txt',array,'delimiter', '\t', 'precision', 10); % tab separated values
xlswrite('matlabarray2.xls',array);
csvwrite('matlabarray3.csv',array); % comma separated values
writematrix(array, 'matlabarray4.csv');
writetable(table(array), 'matlabarray5.csv')
サイズ750ポイント×13の対象のERPデータに3つの条件をクリアするerpdata 前のセクションで得られた。 3つの条件があると想像してみてください erpdata ‘erpfile.txt’ は、
[STUDY erpdata erptimes] = std_erpplot(STUDY,ALLEEG,'channels',{ 'FP1'}, 'noplot', 'on');
dlmwrite('erpfile.txt',squeeze([ erptimes' erpdata{1} ones(size(erpdata{1},1),1)*1 ]),'delimiter', '\t', 'precision', 2);
dlmwrite('erpfile.txt',squeeze([ erptimes' erpdata{2} ones(size(erpdata{2},1),1)*2 ]),'-append', 'delimiter', '\t', 'precision', 2);
dlmwrite('erpfile.txt',squeeze([ erptimes' erpdata{3} ones(size(erpdata{3},1),1)*3 ]),'-append', 'delimiter', '\t', 'precision', 2);
n x m の条件設定の場合:
dlmwrite('erpfile.txt',squeeze([ erpdata{1,1} ones(size(erpdata{1,1},1),1)*[1 1] ]),'delimiter', '\t', 'precision', 2);
dlmwrite('erpfile.txt',squeeze([ erpdata{1,2} ones(size(erpdata{1,2},1),1)*[1 2] ]),'-append', 'delimiter', '\t', 'precision', 2);
dlmwrite('erpfile.txt',squeeze([ erpdata{2,1} ones(size(erpdata{2,1},1),1)*[2 1] ]),'-append', 'delimiter', '\t', 'precision', 2);
dlmwrite('erpfile.txt',squeeze([ erpdata{2,2} ones(size(erpdata{2,2},1),1)*[2 2] ]),'-append', 'delimiter', '\t', 'precision', 2);
被験者をケースとして使用する場合、通常のフォームでデータを保存できます。 erpdata 条件 1 は 750 ポイントと 13 件を含み、長いフォームでデータを保存すると、このように見えます。 このファイルは、2つの列のみ、対象のインデックスの1つと1つが含まれます。
dlmwrite('erpfile.txt',[ erpdata{1}(:,1) ones(size(erpdata{1},1),1)*1],'delimiter', '\t', 'precision', 2);
for iSubject = 2:size(erpdata{1},2)
dlmwrite('erpfile.txt',squeeze([ erpdata{1}(:,iSubject) ones(size(erpdata{1},1),1)*iSubject]),'-append', 'delimiter', '\t', 'precision', 2);
end
ERPとは この例では、12の周波数×12の時間×71チャンネル×13被験者です。
chanlocs = eeg_mergelocs(ALLEEG.chanlocs);
[STUDY erspdata ersptimes erspfreqs] = std_erspplot(STUDY,ALLEEG,'channels',{chanlocs.labels}, 'noplot', 'on');
erspdata =
2×1 cell array
{10×12×71x13 single}
{10×12×71x13 single}
if exist('erpfile.txt'), delete('erpfile.txt'); end
for iFreq = 1:10
for iTime = 1:12
for iChan = 1:71
for iSubject = 1:13
dlmwrite('erspfile.txt',squeeze([ erspdata{1}(iFreq,iTime,iSubject) iFreq iTime iChan iSubject 1]),'-append', 'delimiter', '\t', 'precision', 2);
dlmwrite('erspfile.txt',squeeze([ erspdata{2}(iFreq,iTime,iSubject) iFreq iTime iChan iSubject 2]),'-append', 'delimiter', '\t', 'precision', 2);
end
end
end
end
以下は、保存したファイルの先頭に列名を追加しています。 スクリプトを変更して、自動的に追加することもできます。 これは一例です。 実際の周波数と時間は保存されるだけでなく、交換する erspfreqs(iFreq) そして、 ersptimes(iTime) 上記のスクリプトで。
コンポーネント対策の計算とプロット
コンポーネントの複雑な対策
関数 pop_precomp.m 関数 また、測定を計算するために使用することができます コンポーネントを扱う。 チャネルを扱うときとして、機能 std_precomp.m は、 また、プレコンピューティングコンポーネント 対策 構文は両方のケースで非常に似ています。 インスタンス、関数 pop_precomp.m 関数 次の方法で呼ばれる コンポーネントのコンピューティング対策のためのグラフィックユーザーインターフェイスを起動します。
[STUDY ALLEEG] = pop_precomp(STUDY, ALLEEG, 'components'); % pop up graphical interface
同じ操作を使わなくても実行できます。 の関数 の 24 GUI std_precomp.m は、 型を定義するパラメータで呼び出されます。 計算したい測定。 例えば、次のコードで あらゆるコンポーネントを計算する。
[STUDY ALLEEG] = std_precomp(STUDY, ALLEEG, 'components', 'recompute', 'on', 'erp', 'on', 'filter', 30);
計算された措置の種類は、密接な関係にあります 仮説をテストし、措置の選択 技術的に実行できる分析の種類を制約します。 例えば、次のセクションでは、各コンポーネントからの対策は、 ICAコンポーネントのクラスタリングについて。 EEGLAB jargon は、 先着順 レベルは、プロットに使用するために事前に入力する必要があります。 それから、先に プリクラスタリング、使用される措置の慎重な評価、および その世代で使用するパラメータは、運ぶ必要があります。
以下は、対策を生成するために使用されるコードです。
[STUDY ALLEEG] = std_precomp(STUDY, ALLEEG, 'components',...
'erp','on','erpparams',{'rmbase' [-200 0] },...
'scalp','on',...
'spec','on','specparams',{'freqrange' [3 50] 'specmode' 'fft' 'logtrials' 'off'},...
'ersp','on','erspparams',{'cycles' [3 0.8] 'nfreqs' 100 'ntimesout' 200},...
'itc','on');
コンポーネントの前処理とクラスタリング
ICAコンポーネントのクラスタリングでは、通常、パワースペクトル、ERP、ERSPなどの測定値を事前計算します。ここでは、[3 30] Hzの周波数範囲、[100 600] msのERP時間窓、および上記のデフォルト値を指定する例を示します。
>> [STUDY ALLEEG] = std_preclust(STUDY, ALLEEG, 1,...
{'spec' 'npca' 10 'weight' 1 'freqrange' [3 25] },...
{'erp' 'npca' 10 'weight' 1 'timewindow' [100 600] 'erpfilter' '20'},...
{'dipoles' 'weight' 10},...
{'ersp' 'npca' 10 'freqrange' [3 25] 'timewindow' [-1600 1495] 'weight' 1 'norm' 1 'weight' 1});
または、グラフィックインターフェイスでこれらの値を入力するには、次のようにします。
>> [STUDY ALLEEG] = pop_preclust(STUDY, ALLEEG);
コマンドラインからクラスターコンポーネントを作成するには、次のようにします。
>> [STUDY] = pop_clust(STUDY, ALLEEG, 'algorithm','kmeanscluster', 'clus_num', 10);
またはグラフィックインターフェイスをポップアップする:
>> [STUDY] = pop_clust(STUDY, ALLEEG);
コンポーネントクラスターの可視化
コンポーネントクラスターを視覚化するための主な機能 pop_clustedit.m 関数 このインターフェイスをポップアップするには、単にタイプします。
>> [STUDY] = pop_clustedit(STUDY, ALLEEG);
この関数は、プロットするためのさまざまなプロット関数を呼び出します。
- scalpのマップstd_topoplot.m の使い方),
- パワースペクトル ( )std_specplot.m は、),
- 同等のダイポール (等価ダイポール)std_dipplot.m は、),
- ERPsについてstd_erpplot.m は、),
- ERSPs()std_erspplot.m は、),
- ITCs(イッツ)std_itcplot.m は、).
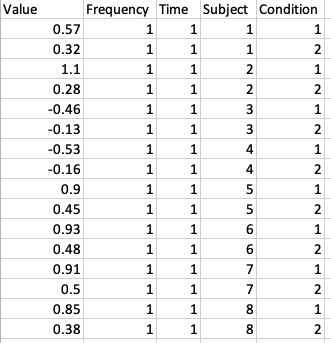
これらの関数のすべてが同じ呼び出し形式に従う (ただし) std_dipplot.m は、 若干異なります。ヘルプメッセージを参照してください。 機能の使用 std_topoplot.m の使い方 例として、次のコードがプロットされます。 クラスターの平均スカルプマップ2:
>> [STUDY] = std_topoplot(STUDY, ALLEEG, 'clusters', 2, 'mode', 'together');
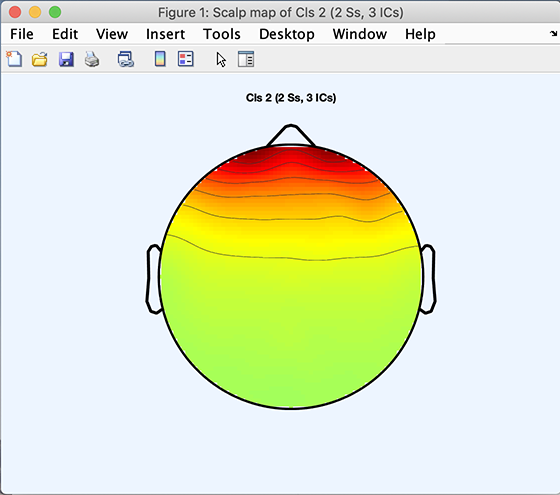
以下のコードスニペットは、クラスタ3の平均スカルプマップをプロットします クラスタ3に属するコンポーネントのスカルプマップ:
>> [STUDY] = std_topoplot(STUDY, ALLEEG, 'clusters', 2, 'mode', 'apart');
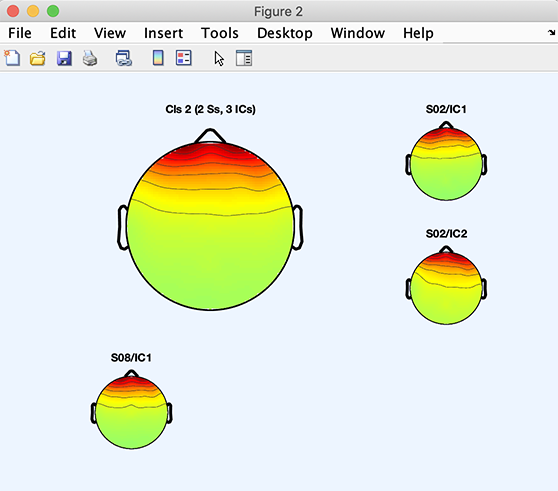
次のコードは、クラスタ2のコンポーネント3をプロットします。
>> [STUDY] = std_topoplot(STUDY, ALLEEG, 'clusters', 2, 'comps', 3);
カスタム対策の計算とプロット
カスタム対策の計算
このサイトは、EEGLAB 2021.0 以降で公開されています。 STUDYのカスタム対策をSTUDYで計算します。 std_precomp.m は、 機能。 カスタムを呼び出す前に 機能、 std_precomp.m は、 関数は便利なようにデータセットの修飾語を適用します rmclust、rmicacomps かinterp は、 カスタムパラメータ *カスタムパラメータ カスタム機能へのパラメーター。
まず関数を呼び出します std_precomp.m は、 変換された単一致命的なデータを格納する。 例えば、ベースライン(820のうち1~410のデータサンプル)を外します。 単一のトライアルを変更したくない場合は、後で説明するように読み込みます。
std_precomp(STUDY, ALLEEG, 'channels', 'customfunc', @(data)bsxfun(@minus, data, mean(data(:,1:410,:),2)), 'interp', 'on');
別の例10 は、 Hz の分岐点
std_precomp(STUDY, ALLEEG, 'channels', 'customfunc', @(data)reshape(eegfilt(data(:,:), EEG(1).srate, 0,10,EEG(1).pnts,60,0,'fir1'), size(data)), 'interp', 'on');
私たちが使うのは、 std_readata.m で synonyms versus non-synonyms の各データ配列(820時間)です。
[~, customdata] = std_readdata(STUDY, ALLEEG, 'channels', {ALLEEG(1).chanlocs.labels }, 'design', 1, 'datatype', 'custom');
customdata
2×1 cell array
{820×61×1×5 single}
{820×61×1×5 single}
最終寸法はそのままです。 カスタム機能が汎用性のため、各々の2-Dの構成要素を構成します。
[~, erpdata] = std_readdata(STUDY, ALLEEG, 'channels', {ALLEEG(1).chanlocs.labels }, 'design', 1, 'datatype', 'erp');
erpdata
2×1 cell array
{820×61×5 single}
{820×61×5 single}
カスタム対策のプロット
それからあなたは使用することができます std_plotcurve.m の使い方 パープルをプロットする。 例えば、以下の関数はERP を計算します。 各チャンネルとプロット(erpdata の入力 ソース、またはcustomdata の入力 文字列)
std_plotcurve(EEG(1).times, erpdata, 'chanlocs', ALLEEG(1).chanlocs);
customdata = cellfun(@squeeze, customdata, 'uniformoutput', false);
std_plotcurve(EEG(1).times, customdata, 'chanlocs', ALLEEG(1).chanlocs);
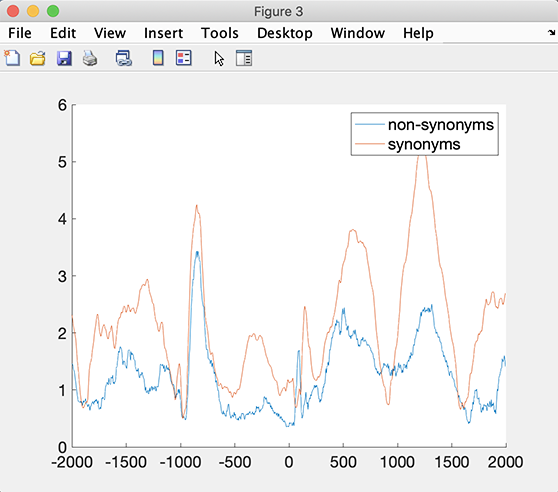
それぞれのチャンネルでroots(RMS)を計算します。
figure;
nCond = length(STUDY.design.variable(1).value);
for iCond = 1:nCond
rms = sqrt(mean(mean(customdata{iCond},3).^2,2));
hold on; plot(EEG(1).times, rms);
end
legend(STUDY.design.variable(1).value)
setfont(gcf, 'fontsize', 16); % change font size
カスタム対策に関する統計計算
関数を使うことができることに注意して下さい std_stat.m で customdata と customerp のセルの配列を上回る。 上記は、61チャンネル分の値が返されます。
std_stat(erpdata, 'condstats', 'on', 'mcorrect', 'fdr', 'method', 'permutation')
ans =
1×1 cell array
{820×61 double}
FelTrip では、コードスニペットは、FielTrip のクラス メソッド と 互換性のある 修正 の エキスパートです。
std_stat(erpdata, 'condstats', 'on', 'fieldtripmcorrect', 'cluster', 'fieldtripmethod', 'montecarlo', 'mode', 'fieldtrip')
ans =
1×1 cell array
{820×61 double}
また、低レベル関数を呼び出すこともできます。 スタコンド。 m 点 そして、 スタコンドFieldTrip 直接(追加情報のための機能ヘルプメッセージを参照)。 例えば:
res = statcond(erpdata); size(res)
ans =
820 61