アーティファクト除去のための独立成分分析
独立成分分析(ICA)は、筋電図や眼球運動などのアーティファクトを含むEEGデータから、アーティファクト成分を分離・除去するための強力な手法です。ICAは、データの該当部分を除去することなくアーティファクトを取り除くことができます。 詳しくはICA背景ガイドを参照してください。
目次
ICA分解の実行
EEGのICA分解に関するオンラインチュートリアル動画です。
データの準備と実行
EEGLAB をロードする
メニュー項目ファイルからサブメニュー項目既存のデータセットをロードするを選択してください。EEGLABの「sample_data」フォルダにある「eeglab_data.set」ファイルを選択します。
一般的に、ICAを実行する前にアーティファクトを含むデータ部分を除去することが推奨されます。しかし、このチュートリアルデータセットでは、事前のアーティファクト除去は行っていません。
このデータセットには、既にチャンネル位置情報が含まれています。チャンネル位置情報を持たないデータセットを使用する場合は、編集 → チャネルの場所を選択してチャンネル位置をインポートしてください。
ICAの実行
エポック化(または連続)EEGデータセットのICA成分を計算するには、 ツール → ICAによるデータ分解を選択してください。 この操作はpop_runica.m関数を呼び出します。デフォルトのオプションで実行するには、 Okを押してください。

ICAアルゴリズムについて
EEGLABは複数のICAアルゴリズムをサポートしています。 Infomax ICAはrunica.mで実装されています。Jaderのjader.m、sobi.m、エポックデータ用の修正版SOBI(acsobiro.m)、およびbinica(runica.mのコンパイル済みCバージョン)も利用可能です。
FastICAツールボックスをインストールするか、ICALAB(他のアルゴリズムを含む配布パッケージ)を使用するか、またはPicard(InfomaxのNewton最適化版を実装したEEGLABプラグイン)をインストールすることもできます。
また、AMICAとpostAmicaUtilityプラグインをインストールして、EEGLABでAMICAを実行することもできます。
詳細はICAガイドを参照してください。
注意事項
ここに示されるサンプル分解は、 比較的少数のチャンネル(32チャンネル)とデータポイントを使用しているため、 実験の際にはかなり多くのデータが必要です。 ICA分解を成功させるためには、できるだけ多くのデータを使用してください。 詳しくはICAガイドを参照してください。
チャネルタイプの選択
ICA分解に使用する特定のチャンネルタイプを選択したり、 チャンネル番号のリストを指定することが可能です。 EEGチャンネルとEMGチャンネルが混在している場合、 EEGとEMGの信号は異なる性質を持つため、EEGチャンネルのみで ICAを実行することが推奨されます。これは、異なる信号タイプ間には 共通の容積伝導のような物理的関係がないためです。編集 → チャネルの場所メニュー項目を使用してチャンネル タイプを定義できます。
コマンドライン出力
runica.m は MATLAB で次のテキストを生成します。
入力データサイズ [32,30720] = 32 チャンネル、30720 フレーム。
ロジスティックICAを用いて32個のICAコンポーネントを探索します。
初期学習率 0.001、ブロックサイズ 36。
角度変化(angledelta) >= 60度のとき、学習率を0.9倍にします。
wchange < 1e-06 または 512 ステップ後にトレーニングを終了します。
オンラインバイアス調整を使用します。
各チャネルの平均を除去中...
最終学習データ範囲: -145.3 から 309.344
球面化行列を計算中...
開始重みは単位行列です...
データを球面化中...
ICAトレーニング
ステップ1 - lrate 0.001000、wchange 1.105647
ステップ2 - lrate 0.001000、wchange 0.670896
ステップ3 - lrate 0.001000、wchange 0.385967、angledelta 66.5 deg
ステップ4 - lrate 0.000900、wchange 0.352572、angledelta 92.0 deg
ステップ5 - lrate 0.000810、wchange 0.253948、angledelta 95.8 deg
ステップ6 - lrate 0.000729、wchange 0.239778、angledelta 96.8 deg
...
ステップ55 - lrate 0.000005、wchange 0.000001、angledelta 65.4 deg
ステップ56 - lrate 0.000004、wchange 0.000001、angledelta 63.1 deg
負の活性化の極性を反転: 1 -2 -3 4 -5 6 7 8 9 10 -11 -12 -13 -14 -15 -16 17 -18 -19 -20 -21 -23 24 -25 -26 -29 -29 -30 31 -32
平均投影分散の降順でコンポーネントをソート中...
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
runica.mで実装されたInfomaxは、デフォルトではスーパーガウス分布 (ガウス分布よりも尖った分布)を持つ成分のみを学習できます。 “extended”オプション(デフォルトで設定済み)を使用すると、 ラインノイズやゆっくりした活動などのサブガウス分布を持つ ソースも検出できます。
‘stop’, 1E-7”の設定を試すことで、より詳細な分解が得られる場合があります。 特に高密度アレイデータでは、より長い学習が より良い分解を返す可能性があります。
ICAを2回実行すると、runica.mは異なる成分の順序、頭皮 トポグラフィ、および最良一致成分のアクティビティタイムコースを返します。 これは、ICAが毎回ランダムな重み行列で初期化され、 各データポイントの順序をランダムにシャッフルするためです。 これは問題でしょうか?少なくとも、同じデータの分解は安定しているべきです。 RELICAプラグインを使用してICA分解の安定性を評価できます。
異なるデータサブセットで学習された分解の違いには いくつかの原因があります。繰り返し分解して評価することは 一般的に推奨されませんが、妥当なアプローチです。
以下では、返されたコンポーネントの特性を検討します。 目的は、どのコンポーネントを研究するか、そしてどのように それらを研究するかを決定することです。
ICAコンポーネントの検査
runica.mが返すコンポーネントの順序は、各コンポーネントがEEGデータの分散にどれだけ貢献するかを反映しています。順序が上位のコンポーネントほど、より多くのデータ分散(脳活動および/またはアーティファクト)を占めます。
コンポーネントの活性化によるスクロール
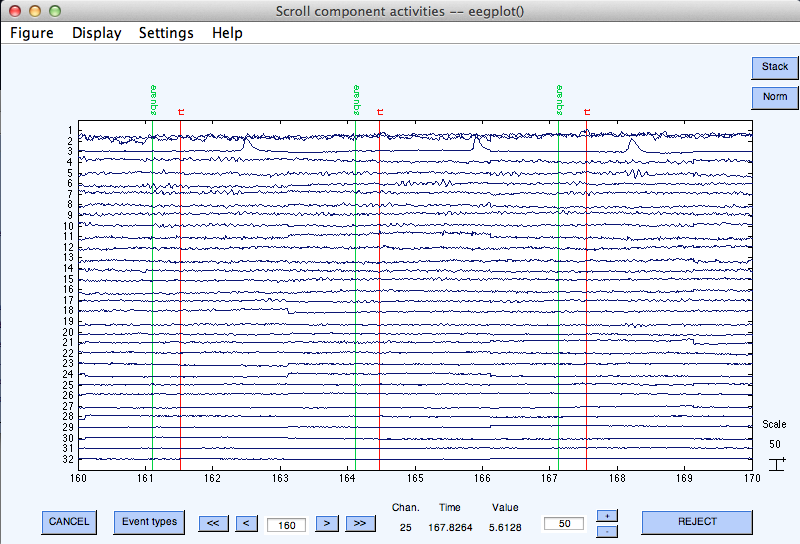
コンポーネントのアクティベーション(タイムコース)をスクロールするには、 Plot → コンポーネントのアクティベーション(スクロール)を選択してください。 ICAアクティベーションを表示することで、 特徴的なアーティファクトを特定できます。例えば、 eegplot.mでスクロール表示すると、コンポーネント3は主に眼球運動アーティファクトを反映していることがわかります。
2Dコンポーネントのスカルプマップ
2Dスカルプコンポーネントマップをプロットするには、Plot → コンポーネントマップ → 2Dを選択してください。 この機能はpop_topoplot.m関数によって実行されます。 デフォルトではすべてのコンポーネントが表示されます。
注記: チャンネル数やPlot geometryの設定に応じて、複数の図が生成される場合があります。チャンネルの小さなグループごと(例:1:30、31:60など)に分けて実行してください。以下では、最初の12コンポーネント(1:12)のみを表示し、オプションとして’electrodes’, ‘off’を指定しています。
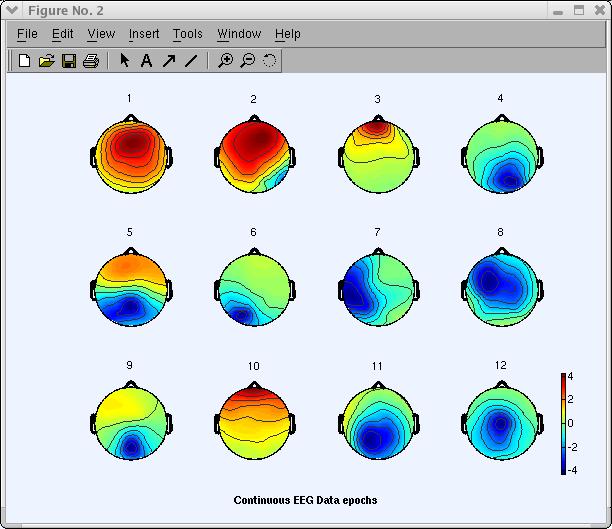
以下のtopoplot.mウィンドウには、選択したコンポーネントのスカルプマップが表示されます。以下のプロットのスケールは任意単位です。コンポーネントのアクティベーションタイムコースも任意単位を使用します。ただし、コンポーネントのスカルプマップにアクティベーションタイムコースを掛け合わせると、元のデータと同じ単位になります。
ICAコンポーネントの調査とラベリング
独立成分の種類を認識する方法を学ぶことが重要です。 以下ではコンポーネントの自動分類についても説明します。
コンポーネントが 1) 脳関連、2) 筋肉のアーティファクト、または 3) その他のタイプの アーティファクトであるかを判断する主な基準は以下の通りです:
- まず、スカルプマップ(上図のように)、
- 次にコンポーネントのタイムコース、
- 次にコンポーネントアクティビティのパワースペクトル、
- 最後にERPイメージ (イベント関連データエポックのデータセットの場合)、 erpimage.mによる表示です。
以下のスカルプマップを見ると (前述のように、あなたの分解とコンポーネントの順序は 若干異なる場合があります)、経験者の目はコンポーネント3(下図)を眼球 アーティファクトコンポーネントとして識別します。
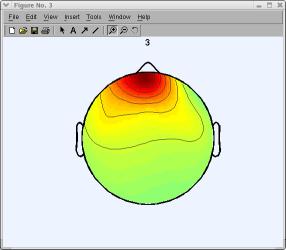
コンポーネントのプロパティを表示し、拒否するコンポーネントにラベルを付ける(すなわち、 データから減算するコンポーネントを識別する)には、 ツール → マップによるコンポーネントのインスペクト/ラベルを選択してください。
前述の2Dスカルプマッププロットとの違いは、各コンポーネントの スカルプマップをクリックするとそのコンポーネントのプロパティが表示されることです。
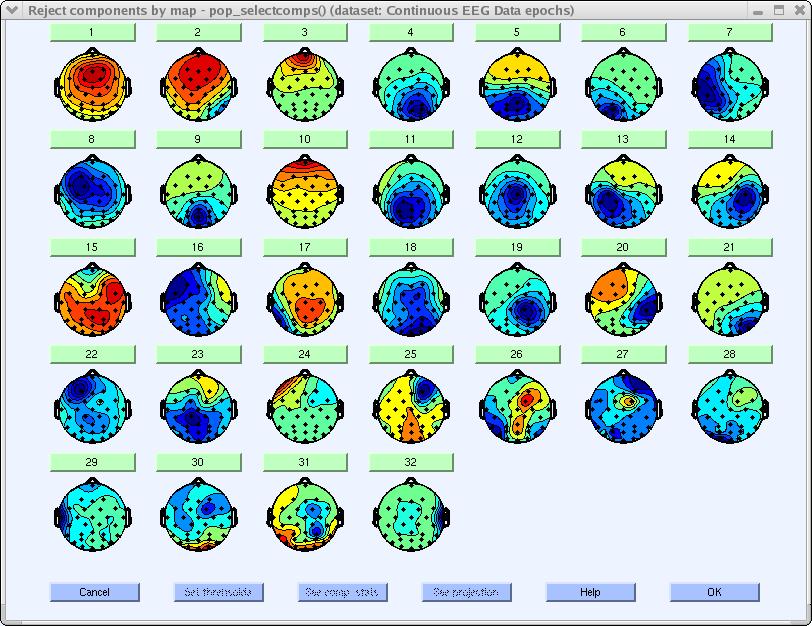
たとえば、3とラベルされたボタンをクリックしてください。このコンポーネントは以下の3つの理由から眼球アーティファクトとして識別できます:
- スカルプマップは眼球 アーティファクトに典型的なパターンを示しています。
- スカルプマップは眼球アーティファクトに典型的な強い前頭部への投射を示しています。
- erpimage.m(右上のパネル)で個々の眼球運動を確認できます。
EEGデータセットでは、通常、アクティベーションの振幅が大きいこと(眼球運動は 大きな振幅を持つため)およびスカルプトポグラフィ(側方の眼球 運動の場合)から判断できます。眼球瞬目を反映する場合はコンポーネント3のように、 眼球運動を反映する場合はコンポーネント10(上図)のように見えます。
コンポーネントプロパティ図は、Plot → コンポーネントプロパティを選択して直接アクセスすることもできます(チャンネルにも同等のメニュー項目があります:Plot → チャネルプロパティ)。
アーティファクトコンポーネントは、コンポーネントのタイムコースを視覚的に 検査することでも識別しやすいです (メニューPlot → コンポーネントのアクティベーション(スクロール)を使用してください)。
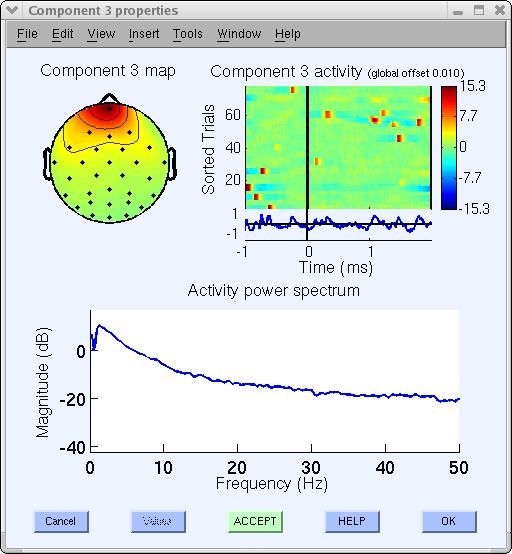
このコンポーネントは眼球活動を反映しているため、さらなる分析とプロットの前にデータから減算したい場合があります。 下部の緑色のAcceptボタン(上図)を 赤色のRejectボタンに切り替えてください(注意: この時点では、コンポーネントは拒否のためにマークされるだけです。マークされた コンポーネントを実際にデータから減算するには、後述のセクションを参照してください)。 Okを押してコンポーネントプロパティウィンドウを閉じます。
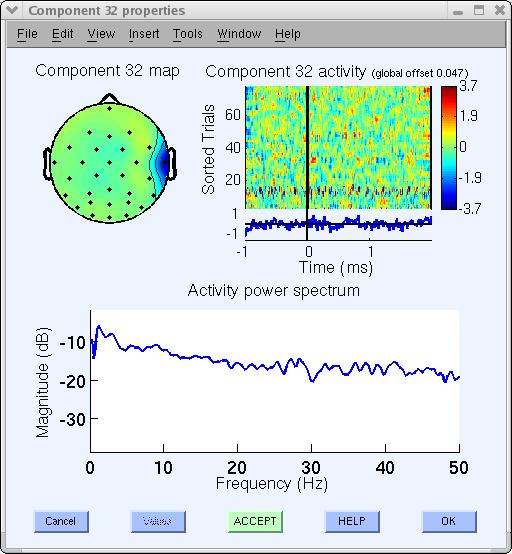
この分解におけるもう一つのアーティファクト例はコンポーネント32です。典型的な筋肉アーティファクトコンポーネントであるように見えます。このコンポーネントは以下に示すように、高周波帯域(20-50Hz)で高いパワーを持っています。
よく遭遇するアーティファクトコンポーネント(ただし、この分解には存在しません)として、 単一チャンネルの「故障」や、ラインノイズのアーティファクトがあります。 ラインノイズコンポーネントはERPに影響を与えませんが、 60Hzのラインノイズを含むパワースペクトルプロットに影響します。 特に65チャンネル以上のデータでよく見られます。
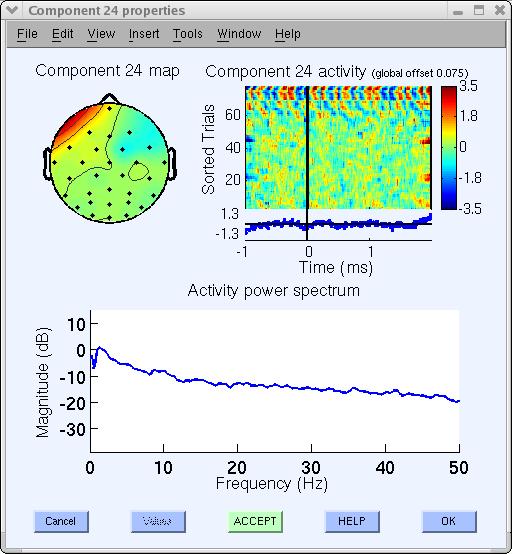
他の多くのコンポーネントは脳関連であるように見えます。チュートリアルの別のセクションでは、双極子フィッティング(DIPFIT)を使用した脳源推定を扱います。 コンポーネントが「半分アーティファクト、半分脳関連」の場合はどうすればよいでしょうか? これは判断が難しい場合がありますが、
経験則として、特定の種類のアーティファクトを含むデータ領域を事前に除去しておくことが、「きれいな」ICAコンポーネントを得るために非常に有用です。
ICAのヒント
より良いICA分解を得る方法
ICAは、固定されたスカルプマップ(すなわち、スカルプ分布)を持つソースのみを分離できます。複雑な動きのアーティファクトなど、固定されていないスカルプマップを持つノイズは、独立に分解可能なデータ特徴として認識されません。その場合、多くの単一チャンネルのノイズ対応コンポーネントを含むコンポーネントマップが生成されます。脳関連の成分に対応するコンポーネントの数(および質)が低下します。
データをきれいにすることが、良いICA分解を得るための最善の戦略です。ノイズの多いICAコンポーネントを削除することも有効です。
ハイパスフィルタリングとICA
データが1Hz以上、または2Hz以上でハイパスフィルタリングされている場合、ICA分解(コンポーネントの質)はより良くなります。しかし、ハイパスフィルタリングはERP分析など、低周波成分が重要な分析に影響を与える可能性があります。以下の手順で対処できます:
- フィルタリングなし(または最小限のフィルタリング)のデータセット(データセット1)で開始
- 1Hz または 2Hz でハイパスフィルタリングし、データセット2を作成
- データセット2でICAを実行
- ICAの結果をデータセット1に適用します。ICA重みと球行列をデータセット2からデータセット1にコピーするには、編集 → データセット情報メニューで、ICA重み行列の編集ボックスにALLEEG(2).icaweights、ICA球行列の編集ボックスにALLEEG(2).icasphereと入力し、Okを押します。
ICAコンポーネントはフィルタリングされたデータ空間で学習されますが、フィルタリングされていないデータに適用してもアーティファクト除去は有効に機能します。2Hzのハイパスフィルタリングがこの方法で問題なく機能することが示されています。
アーティファクト除去とICA
Clean Rawdataなどのツールでデータをクリーニングした後にICAを実行する場合、同様の手順が適用できます:
- フィルタリングなし(または最小限のフィルタリング)のデータセット(データセット1)で開始
- EEGLABのクリーニングツールを使用してデータをクリーニングし、データセット2を作成
- データセット2でICAを実行
- ICAの結果をデータセット1に適用します。ICA重みと球行列をデータセット2からデータセット1にコピーするには、編集 → データセット情報メニューで、ICA重み行列の編集ボックスにALLEEG(2).icaweights、ICA球行列の編集ボックスにALLEEG(2).icasphereと入力し、Okを押します。
この手順は、以前に説明したハイパスフィルタリングと同様に有効です。重要な条件は、ICA分解がクリーニングされたデータで行われることです。
破損したICA分解への対処方法
Infomax ICA(EEGLABのデフォルト)では、2つのコンポーネントのアクティビティが互いに打ち消し合うことがあります。どちらのコンポーネントもほぼ同一で反対の極性を持ちます。この場合、両方のコンポーネントに大量のノイズが見られます。 以下に例を示します。
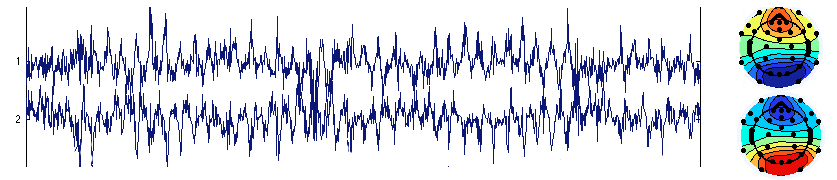
ランク不足(次のセクションで説明)の場合にこれが発生することがありますが、フルランクのデータでも起こることがあります。この問題に対する明確な解決策はありません。1つの方法は別のICAアルゴリズムを使用することです。 別の方法はPCA次元削減を使用することです。 例えば32チャンネルで、10次元まで削減すると問題が解消される場合があります(20に削減)。以下は同じデータですが、 PCAで次元削減した後にICA分解を行ったものです(上記の2つのコンポーネントに対応するコンポーネントのみ表示)。 この単一コンポーネントは上記の両方のコンポーネントのアクティビティを反映していますが、 アクティベーション中のノイズが消えています(つまり、他のコンポーネントにより適切に割り当てられています)。 ここでの問題は、ICAが互いの活動を補い合う2つのコンポーネントを生成する傾向があることです。 正式な比較は実施していませんが、上記の2つの非常にノイズの多い コンポーネントを単に削除するよりも、PCA次元削減による解決が好ましいと考えています。これは、上記の2つのコンポーネントが他のコンポーネントもよりノイズの多いものにする傾向があるためです。

PCAについて補足すると、PCAは非線形性を導入する場合がありますが、 可能な限りフルランクのデータ行列を使用することを推奨します。
ゴーストICAコンポーネントに関する詳細は、この論文およびこの論文を参照してください。
データランク不足の問題
データが平均参照されている場合、各タイムポイントにおいて最後のチャンネルのアクティビティは他のすべてのチャンネルの和のマイナスに等しくなります。ICAは、このランク不足のケースでは問題が生じます。
pop_runica()関数はランク不足を検出し、自動的にPCA次元削減を適用します。
しかし、MATLABのランク計算は、特に生のEEGデータが単精度行列として格納されている場合、信頼性が低いことがあります。そのため、平均参照によるランク低下が検出されない場合があります。
例えば64チャンネルのデータを平均参照した場合、ICAオプションの編集ボックスに ‘pca’, 63のオプションを指定してください。これをしないと、データに最も貢献するコンポーネントの1つが重複する可能性があります(前述のセクションで説明した通りです)。
ICA前の積極的なアーティファクト除去の問題
ICAを実行する前にデータをきれいにすることは重要です。しかし、積極的なアーティファクト除去はデータポイント数を減少させ、ICA分解の質に影響する可能性があります。推奨される手順は以下の通りです:
- 最小限のクリーニング(または不良チャネルのみの除去)を行ったデータセットで開始
- このデータセットでICAを実行
- ICAコンポーネントを使用してアーティファクトを除去
- 必要に応じて、より積極的なしきい値や戦略を使用して、残りのアーティファクトを除去
エポック化データとICA
一般的に、エポック化されたデータに対してICAを実行することは問題ありません。エポックのベースラインを除去しておくことが重要です。ICAに関する論文では、各エポックのベースラインを除去してからICAを実行し、その後ICAベースラインを除去することを推奨しています。
ICAは連続データとエポック化データの両方で実行できます。 エポック化データはエポック内で定常的である傾向があります。しかし、 すべての条件のエポックが統計的に類似していることが条件です。 より長いエポックは、ICA学習のためにより多くのデータを提供するため好ましいです。
なお、ICAをエポック化データに適用する場合、ターゲット刺激にタイムロックされたエポックには、前のイベントの一部が含まれている可能性があります。 pop_runica.mは データサンプルの時間順序を考慮せず、トレーニング中にランダムな順序でサンプルを選択します。そのため、連結されたデータセットのサンプルは、より頻繁にトレーニングに使用される傾向があります。エポックの開始時間は前のエポックの終了時間より前であってはならず、終了時間は次のエポックの開始時間を超えてはいけません。
再参照とICA
データを再参照した場合、ICAを再実行する必要があります。ICAは参照に依存するため、再参照後はICA分解が無効になります。特に、新しい参照によりデータランクが変わる可能性があることに注意してください。EEGLABは、再参照後にICAの再実行を促すメッセージを表示します。
コンポーネント自動検出
ICLabel(Luca Pion-Tonachiniによるプラグイン)を使用して、EEGLABでICAコンポーネントを自動的に分類できます。ICLabelは、脳活動、眼球運動、筋肉活動などのカテゴリにコンポーネントを分類するニューラルネットワークベースのICの分類器です。数千のラベル付きICと数千の未ラベルICで学習されています。詳細はICLabelに関する論文およびICLabelウェブサイトを参照してください。ICLabelを実行するには、メニューツール → ICLabel → コンポーネントを分類を選択してください。

以下のウィンドウが開きます。Okを押してください。
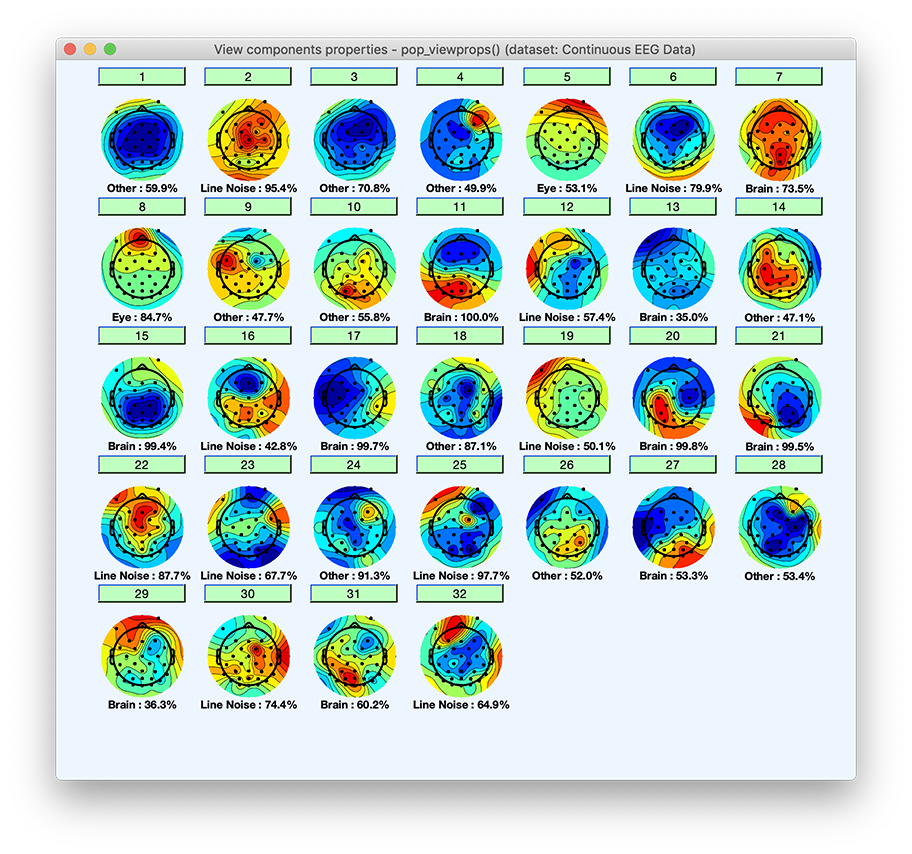
コンポーネントをクリックすると、拡張されたコンポーネントプロパティと 各カテゴリに属する推定確率を表示するウィンドウがポップアップします。
コンポーネントは7つのカテゴリに分類されます:脳、筋肉、眼球、心臓、ラインノイズ、チャネルノイズ、その他。以下のMATLABコマンドで、最初の10コンポーネントの各カテゴリ(列)の確率(%)を表示できます。
>> round(EEG.etc.ic_classification.ICLabel.classifications(1:10,:)*100)
ans =
10×7 single matrix
12 0 1 0 26 1 60
4 0 0 0 95 0 0
10 0 4 0 14 1 71
20 0 0 1 28 1 50
9 0 53 2 9 2 26
5 0 0 1 80 0 14
74 0 0 0 12 0 14
1 0 85 0 8 2 4
7 0 0 0 41 4 48
23 0 0 0 21 0 56
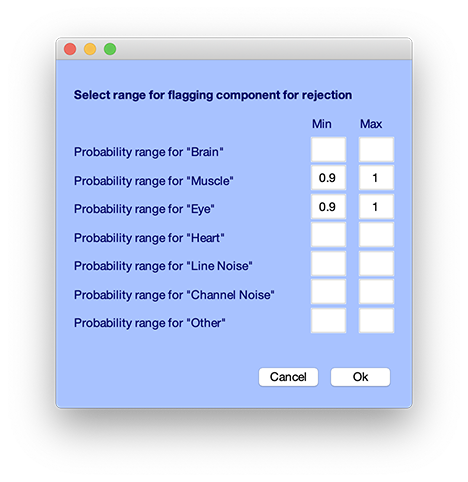
メニュー項目ツール → ICLabel → アーティファクトコンポーネントをフラグ付けを選択してください。デフォルトでは、筋肉や眼球アーティファクト(瞬目と眼球運動)カテゴリで90%以上の確率を持つコンポーネントがフラグ付けされます。この機能でフラグ付けされたコンポーネントは、手動でコンポーネントを拒否するインターフェース(ツール → マップによるコンポーネントのインスペクト/ラベル)で赤色表示されるため、どのコンポーネントがアーティファクトとしてフラグ付けされているかを確認・編集できます。
コンポーネントを分析する
通常は、データセットからすべての独立成分を除去するわけではありません。 要約すると、ICLabelやSTUDY(グループ分析)でのICAコンポーネントの分類、アーティファクトとして識別されたコンポーネントの除去、またはカスタム手法を使用して分析を進めることができます。
コンポーネントをデータから減算したい場合は、 ツール → コンポーネントを削除メニュー項目を選択してください。これは pop_subcomp.m 関数を呼び出します。
結果ウィンドウ(下図)にデフォルトで表示されるコンポーネント番号は、 ツール → マップによるコンポーネントのインスペクト/ラベルで 拒否のためにマークされたもの(AcceptまたはReject ボタン)です。
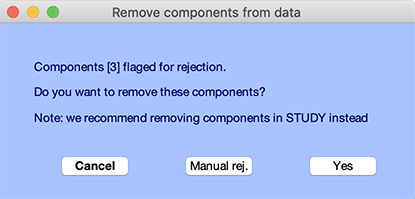
Yesを押すと、選択したコンポーネントがデータから減算されます。

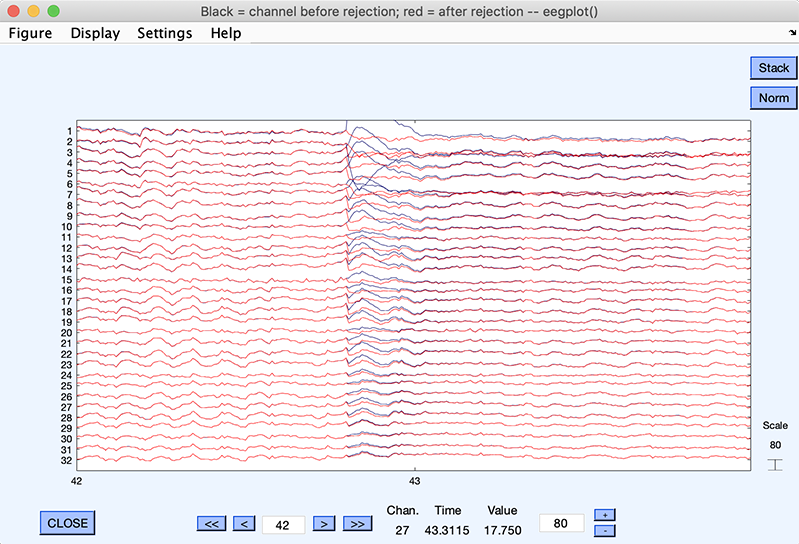
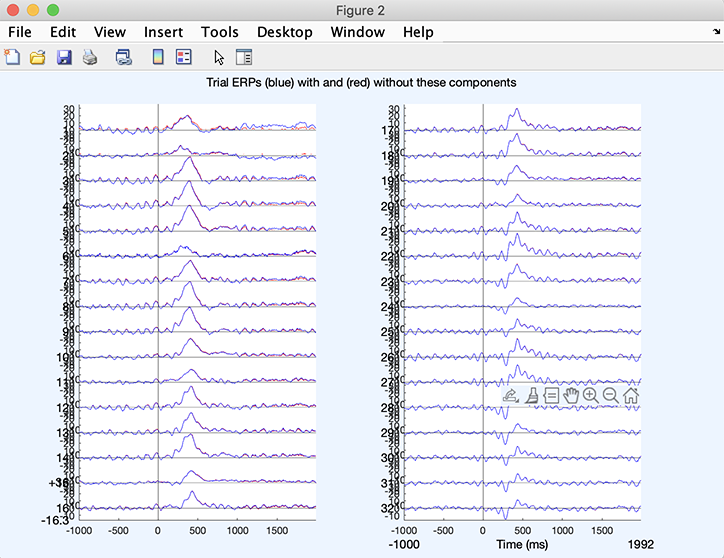
コンポーネント3がデータから減算された新しいデータセットが作成されます。以下のウィンドウはコンポーネント減算前後のデータを表示します。
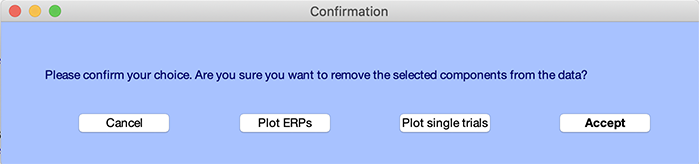
Plot single trialsボタンを押すと、減算前(青)と減算後(赤)のシングルトライアルが表示されます。
Plot ERPsボタンを押すと、 コンポーネント減算前(青)と減算後(赤)のERPが表示されます。
ウィンドウを閉じると、新しいデータセットを保存するかどうかを尋ねるウィンドウが表示されます。